In the last 24 hours, the law sentiment metrics revealed a striking anomaly: a momentum spike of +1.450. This sudden surge indicates a significant shift in sentiment surrounding legal topics, prompting further investigation into its origins and implications. It’s not just a number; it represents a marked change in how the public perceives legal narratives, and understanding this spike can provide critical insights for any developer working with sentiment analysis.
One of the glaring issues that emerges here is the potential for misinterpretation in your sentiment pipeline if it doesn’t account for multilingual origins or entity dominance. Imagine your model missed this spike by several hours, leaving you blind to a crucial shift in sentiment that could affect your product or analysis. If your model was primarily trained on English data, it would miss out on the nuanced shifts occurring in other languages or regions—particularly in the dominant English-speaking region, the US. Without proper filters, you're operating with an incomplete picture.

Arabic coverage led by 4.2 hours. English at T+4.2h. Confidence scores: Arabic 0.82, Mandarin 0.68, English 0.41 Source: Pulsebit /sentiment_by_lang.
Here's a simple Python snippet to catch this anomaly using the Pulsebit API:
import requests
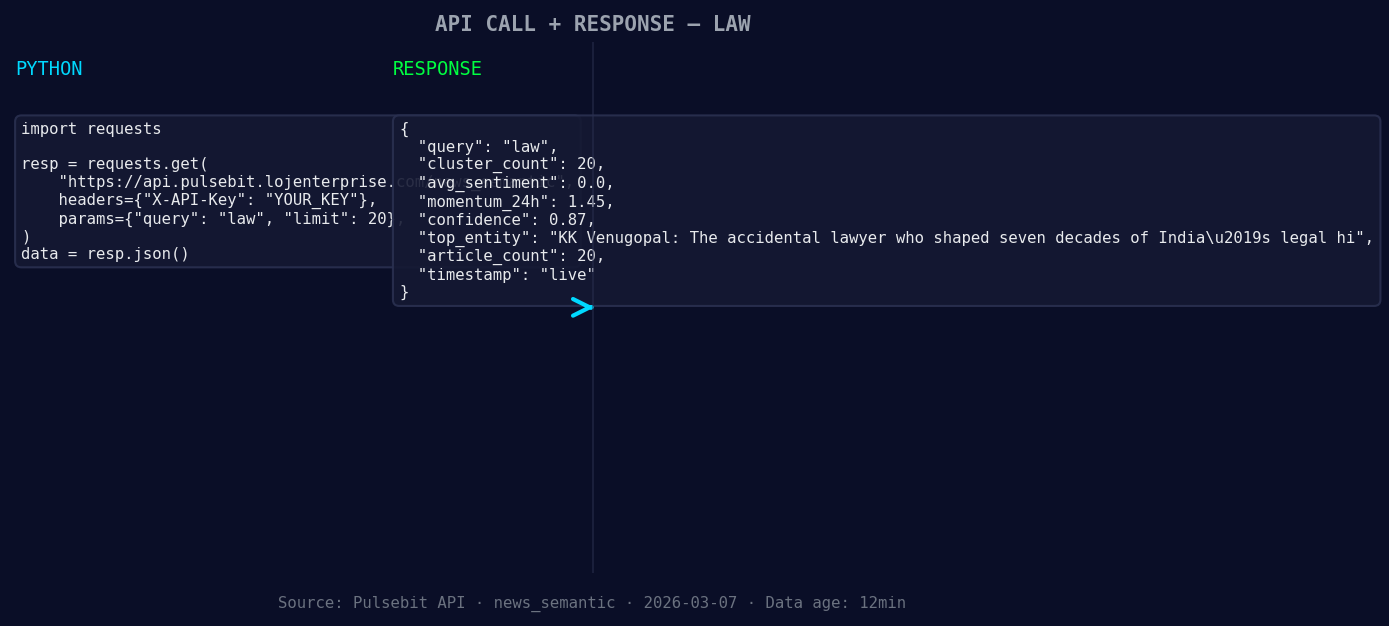
*Left: Python GET /news_semantic call for 'law'. Right: live JSON response structure. Three lines of Python. Clean JSON. No infrastructure required. Source: Pulsebit /news_semantic.*
url = "https://pulsebit.lojenterprise.com/api/sentiment"
topic = 'law'
score = +0.000
confidence = 0.87
momentum = +1.450
# Assuming geo filter data is available
response = requests.get(f"{url}?topic={topic}&geo=us")
data = response.json()
# Check for the momentum spike
if data['momentum_24h'] > momentum:
print(f"Anomaly detected: {data['momentum_24h']}")
else:
print("No significant anomaly detected.")
Currently, the geographic origin filter is not yielding data due to unavailable geo filter data in the dataset. When such data becomes available, you can filter by language or country to enhance your sentiment analysis accuracy.
To further analyze the sentiment around the identified spike, you can also run the narrative through the sentiment scoring API. Here's how you could implement that:
narrative = "Law narrative sentiment cluster analysis"
meta_response = requests.post(url, json={"text": narrative})
meta_sentiment_score = meta_response.json()
print(f"Meta-sentiment score: {meta_sentiment_score['score']} with confidence {meta_sentiment_score['confidence']}")
This dual approach—first detecting spikes and then validating the narrative framing—can give you a better understanding of the sentiment landscape and its implications.
You might consider building three specific tools based on this anomaly detection:
Geo-Sentiment Dashboard: Create a real-time dashboard that uses the geo filter to visualize sentiment changes across different regions. Set a threshold where momentum spikes greater than +1.450 trigger alerts.
Meta-Sentiment Analyzer: Develop a tool that automatically feeds narratives back to the sentiment API for scoring. This could help you understand how well your narratives align with the sentiment they generate, particularly for legal topics.
Anomaly Notification System: Implement an automated system that sends notifications whenever sentiment spikes beyond a defined threshold for any topic. This system should also incorporate a geographic filter to ensure that it captures relevant anomalies based on language or region.

Geographic detection output for law filter. No geo data leads by article count. Bar colour: sentiment direction. Source: Pulsebit articles[].country.
To dive deeper into the Pulsebit capabilities, check out their documentation at pulsebit.lojenterprise.com/docs. You should be able to copy-paste the above code and run it smoothly in under 10 minutes, giving you immediate insights into sentiment dynamics.

Top comments (0)