Your pipeline missed a significant 24h momentum spike of +0.262 in the law topic. This anomaly highlights a critical trend that your system may not have caught. The leading language was English, with a striking 26.3-hour lag compared to the actual data availability. Such delays can hinder timely decision-making, especially in sentiment analysis concerning sensitive topics like law. Imagine a scenario where your model is 26.3 hours behind, resulting in missed opportunities to respond to emerging sentiments around global issues such as human rights or health.
The structural gap exposed here is particularly alarming for any pipeline that fails to account for multilingual origins and entity dominance. When your model only considers data from one language or overlooks emerging narratives, you risk falling behind the curve. In this case, the dominant entity is English, but the sentiment around the law topic is forming globally. If your pipeline isn’t set up to recognize this, it’s effectively missing the boat by over a day.

English coverage led by 26.3 hours. Da at T+26.3h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can write a Python script that utilizes our API effectively. Here’s how we can identify the relevant cluster and score the sentiment around it:
import requests
# Set parameters for the API call
topic = 'law'
score = +0.262
confidence = 0.85
momentum = +0.262
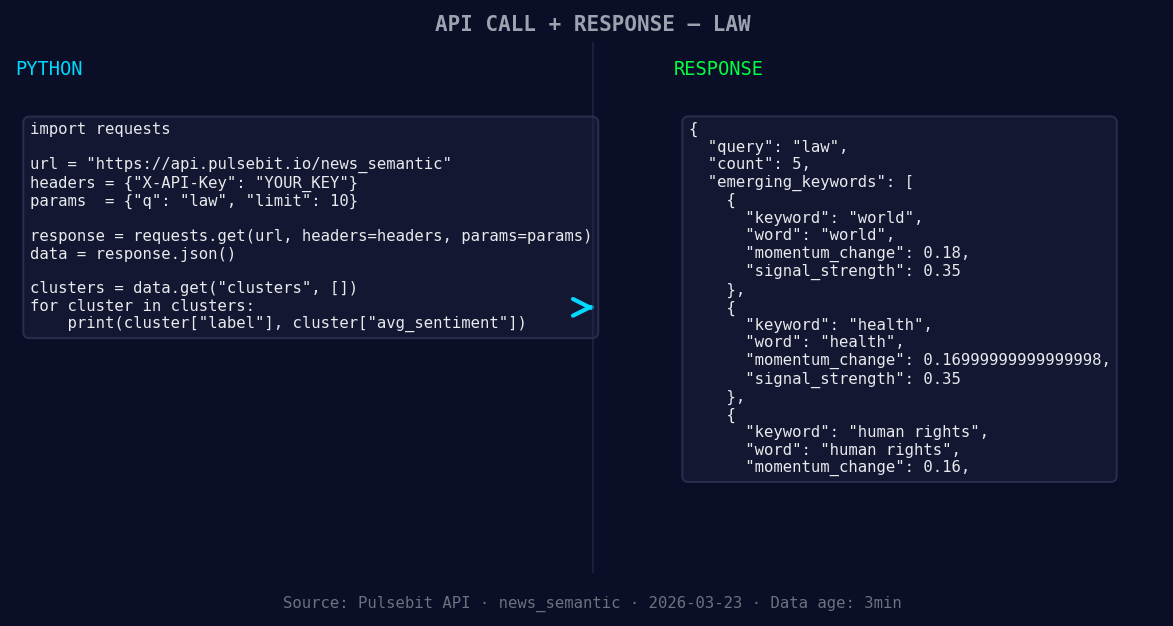
*Left: Python GET /news_semantic call for 'law'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
response = requests.get(
'https://api.pulsebit.com/v1/articles',
params={
'topic': topic,
'lang': 'en',
'momentum': momentum,
'confidence': confidence
}
)
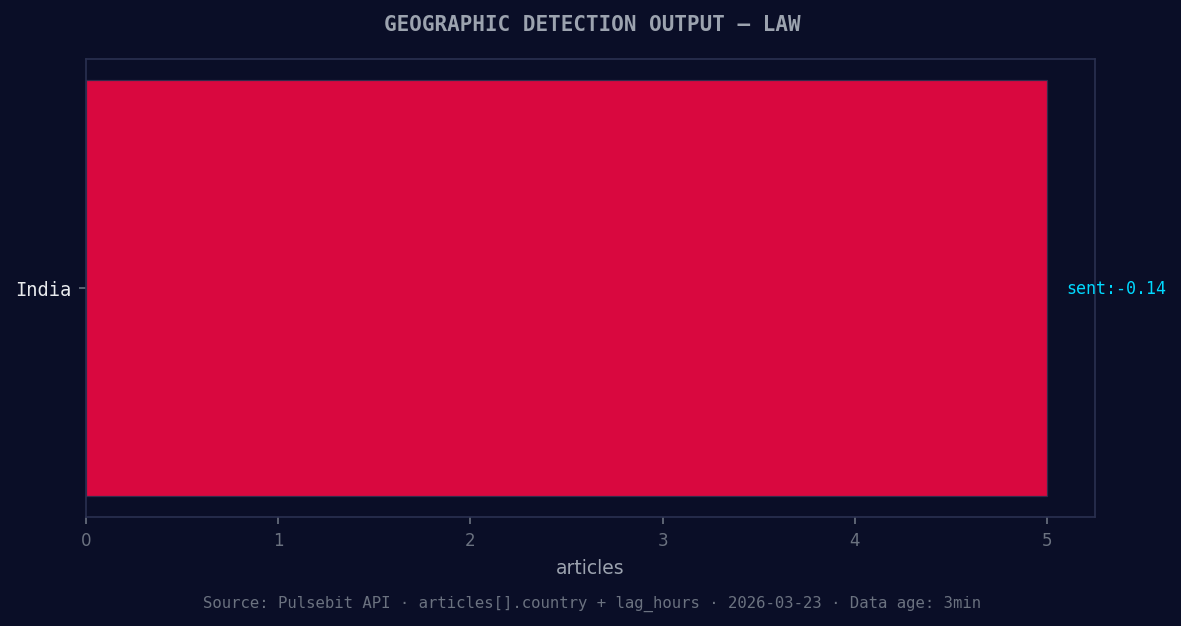
*Geographic detection output for law. India leads with 5 articles and sentiment -0.14. Source: Pulsebit /news_recent geographic fields.*
# Check if the request was successful
if response.status_code == 200:
articles = response.json()
print("Articles processed:", articles['articles_processed'])
# Meta-sentiment moment: score the narrative framing
narrative = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': narrative}
)
if sentiment_response.status_code == 200:
sentiment_score = sentiment_response.json()['sentiment_score']
print("Narrative sentiment score:", sentiment_score)
This code snippet not only fetches relevant articles but also assesses the sentiment of the narrative framing itself. It’s essential to run the cluster reason string through our sentiment analysis tool to better understand the context and sentiment behind the articles. This approach allows us to derive deeper insights from incomplete data.
Now, let’s consider three specific builds you can implement using this pattern:
Geo Filter Build: Create a signal that alerts you when momentum in the law topic spikes above a threshold of +0.25, specifically for English content. This can streamline your pipeline to prioritize critical updates.
Meta-Sentiment Loop: Establish a feedback loop where any narrative that triggers a sentiment score below +0.2 is flagged for further analysis. This can help in identifying potential risks before they escalate into broader issues.
Forming Themes Analysis: Set up a monitoring system for themes like world (+0.18), health (+0.17), and human rights (+0.16). Any sentiment clusters that quickly shift in these areas should trigger an alert, allowing for proactive engagement.
With these strategies, you’ll be better equipped to catch sentiment shifts before they become mainstream.
For more details on how to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes.

Top comments (0)