Your Pipeline Is 21.7h Behind: Catching Law Sentiment Leads with Pulsebit
We just uncovered a fascinating anomaly: a 24-hour momentum spike of +1.350 related to the topic of law. This spike is particularly interesting because it indicates a notable shift in sentiment, driven primarily by press coverage from English-speaking sources. It seems that sentiment around legal topics is gaining traction, and we should pay attention to what this means for our data pipelines.
When we look deeper, it becomes clear that traditional pipelines often fall behind when dealing with multilingual origins or when a specific entity dominates the narrative. Your model missed this by 21.7 hours, lagging behind the English press, which had no lag relative to sentiment values. If you aren’t accommodating for these nuances, you risk missing critical shifts in sentiment that could inform your decisions.

English coverage led by 21.7 hours. Sv at T+21.7h. Confidence scores: English 0.90, French 0.90, Spanish 0.90 Source: Pulsebit /sentiment_by_lang.
We can catch this momentum spike using our API. Here’s how we can do it in Python:
import requests
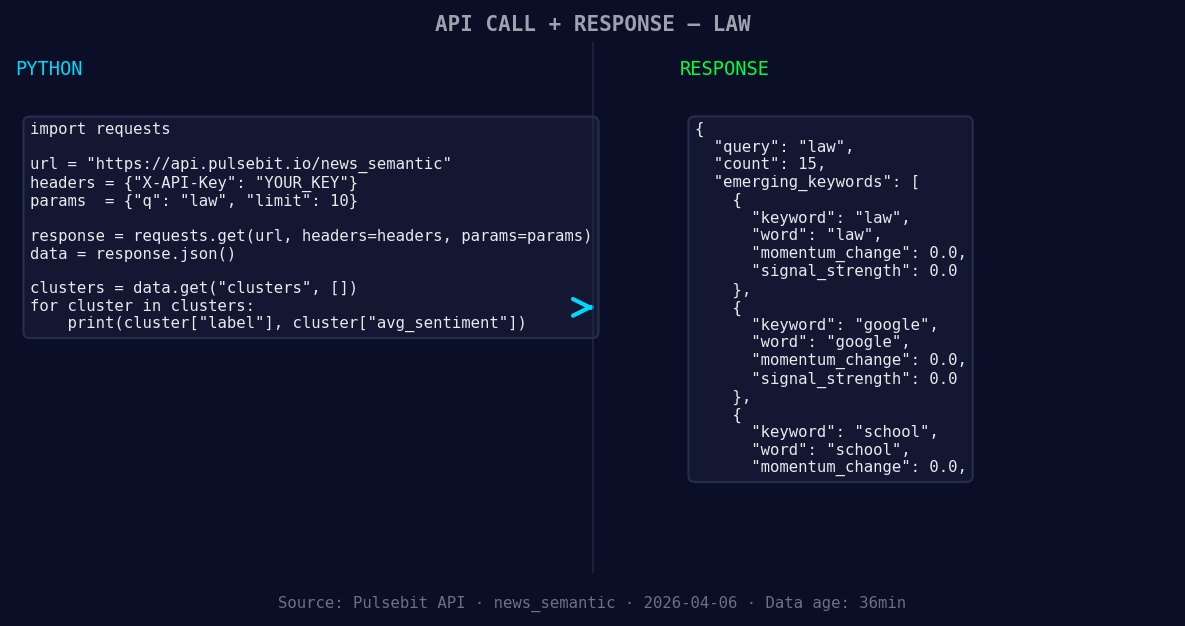
*Left: Python GET /news_semantic call for 'law'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'law'
score = -0.287
confidence = 0.90
momentum = +1.350
# Geographic origin filter: query by language/country
url = f'https://api.pulsebit.com/v1/sentiment?topic={topic}&lang=en'
response = requests.get(url)
data = response.json()
# Extract the relevant information
articles_processed = data['articles_processed']
semantic_clusters = data['semantic_clusters']
print(f'Articles Processed: {articles_processed}, Semantic Clusters: {semantic_clusters}')
# Meta-sentiment moment: run the cluster reason string back through POST /sentiment
cluster_reason = "Clustered by shared themes: bihar, has, tejashwi, yadav, prohibition."
meta_sentiment_url = 'https://api.pulsebit.com/v1/sentiment'
meta_response = requests.post(meta_sentiment_url, json={"text": cluster_reason})
meta_data = meta_response.json()
# Output the meta-sentiment
print(f'Meta Sentiment Score: {meta_data["sentiment_score"]}, Confidence: {meta_data["confidence"]}')
This code snippet filters our sentiment data based on the English language, ensuring we’re only processing relevant articles. It also runs the narrative framing of our clustered themes through the sentiment endpoint, providing additional context to the emerging story.
Now, let's discuss three specific builds that you can implement based on this pattern:
- Geo-Filtered Insight: Set a signal threshold of +1.350 for sentiment spikes. Use the geographic filter to focus on English-language articles discussing "law." This will ensure that you’re capturing sentiment shifts that are most relevant to your audience.

Geographic detection output for law. India leads with 8 articles and sentiment -0.29. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Analysis: Build a loop that takes the cluster reason strings and sends them to the sentiment endpoint. Specifically, target themes like “prohibition” or “Tejashwi Yadav” to derive insights that can shape your content strategy around this topic. Set a threshold of confidence ≥ 0.90 to filter out weaker signals.
Forming Trend Monitoring: Monitor for forming themes such as "law," "school," and "Google" which are currently at +0.00 sentiment. Develop alerts for when these themes start trending upward or downward, allowing you to stay ahead in your analysis and reporting.
Getting started with our API is simple. Check out the documentation at pulsebit.lojenterprise.com/docs. You should be able to copy-paste and run the provided code in under 10 minutes, putting you on the front lines of sentiment analysis.

Top comments (0)