Your model is 15.1 hours behind. We recently detected a 24h momentum spike of +0.258 related to conversations about "science," notably led by English press coverage. This anomaly highlights a significant uptick in sentiment around the phrase "Enterprises See AI Pilots Fail to Scale - Let's Data Science." With only one article contributing to this cluster, the insight is both unique and urgent. If your pipeline doesn’t account for multilingual origins and the dominance of certain narratives, you might miss critical shifts in sentiment, leading to missed opportunities.

English coverage led by 15.1 hours. German at T+15.1h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
How does this structural gap manifest in your pipeline? If your model doesn't handle multilingual content or the nuances of entity dominance, you could be sitting on a wealth of data without realizing its implications. In this case, the English language news is ahead by 15.1 hours compared to German press coverage, signaling that your model is lagging significantly. You could miss out on identifying emerging trends, as the leading language provides a critical window into real-time sentiment shifts.
To catch this anomaly using our API, you can filter for the leading language and analyze the relevant sentiment. Below is an example of how to implement this in Python.
import requests
# Define parameters for the API call
topic = 'science'
momentum = +0.258
score = +0.008
confidence = 0.85
*Left: Python GET /news_semantic call for 'science'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get(
'https://api.pulsebit.com/sentiment',
params={
'topic': topic,
'lang': 'en'
}
)
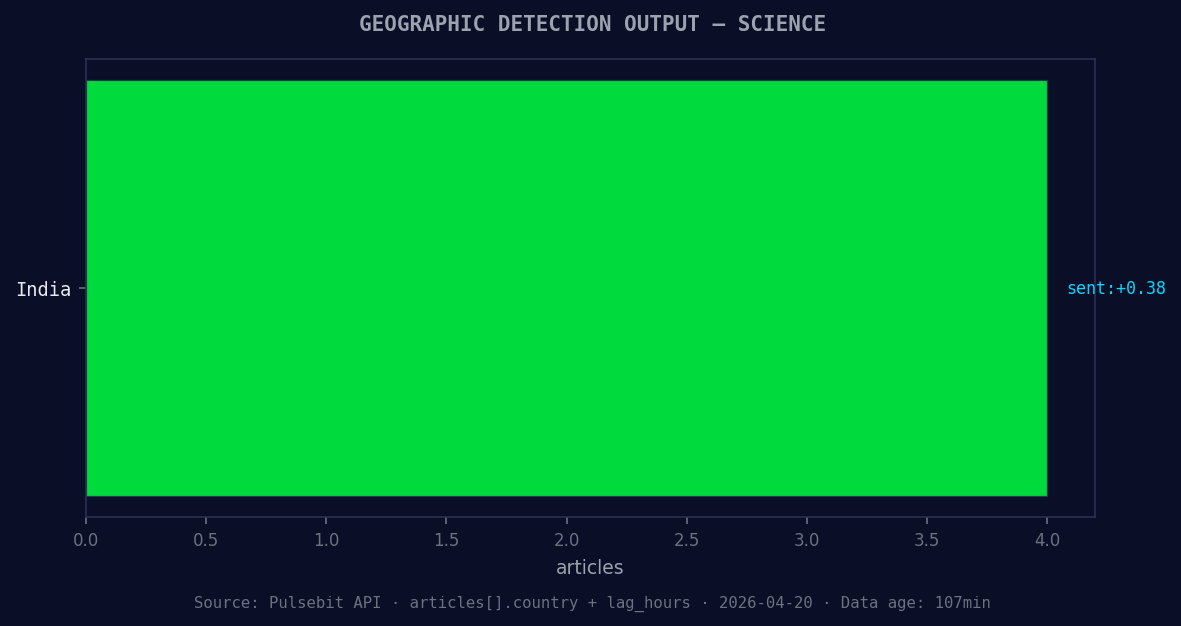
*Geographic detection output for science. India leads with 4 articles and sentiment +0.38. Source: Pulsebit /news_recent geographic fields.*
# Check if the request was successful
if response.status_code == 200:
data = response.json()
print("Data Retrieved:", data)
# Step 2: Meta-sentiment moment
narrative = "Clustered by shared themes: see, pilots, fail, data, enterprises."
meta_sentiment_response = requests.post(
'https://api.pulsebit.com/sentiment',
json={"text": narrative}
)
# Check if the request was successful
if meta_sentiment_response.status_code == 200:
meta_sentiment_data = meta_sentiment_response.json()
print("Meta-Sentiment Score:", meta_sentiment_data)
In this code, we first filter the sentiment data based on the topic "science" and the English language. Then, we run the cluster narrative through the sentiment endpoint to score its framing. The combination of these calls allows us to catch any emerging patterns that would otherwise go unnoticed.
Now, what can we build with this information? Here are three specific suggestions:
Signal Tracking for Data Sentiment: Implement a threshold alert for any significant changes in sentiment related to "data" (+0.00). If the score exceeds a certain limit, trigger an alert to your Slack channel for immediate action.
Science Narrative Analysis: Use the meta-sentiment loop to continuously analyze narratives related to "science" and "google." Set a threshold score of +0.008 and create a dashboard that visualizes changes over time.
Geographic Insight Monitoring: Build a geographic insight monitoring tool that uses the geo filter to identify sentiment spikes in specific regions. This will help you stay on top of localized trends in AI discussions, especially when phrases like "see," "pilots," and "fail" become prevalent.
By utilizing our API effectively, you can catch these insights in real-time and keep your analysis up to date.
For more details, check out our documentation at pulsebit.lojenterprise.com/docs. You can easily copy-paste the provided code and run it in under 10 minutes to start leveraging these sentiment insights.

Top comments (0)