Your pipeline just missed a significant anomaly: a 24h momentum spike of +0.177. This spike is driven by a noteworthy sentiment shift in the cloud sector, particularly surrounding CoreWeave's AI Cloud Deal with Anthropic. With two articles covering this theme, the leading language of the sentiment is English, with a 12.8-hour lead time. This is a crucial insight for us as developers; it highlights the need to be vigilant in our sentiment analysis when dealing with multilingual data and entity dominance.

English coverage led by 12.8 hours. No at T+12.8h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
If your model isn't designed to handle multilingual origins or dominant entities effectively, you could miss out on critical sentiment shifts like this by a staggering 12.8 hours! Imagine trying to act on market sentiment only to realize you’re lagging behind due to a language bias or an oversight of the entities involved. In this case, the dominant entity was Anthropic, and the leading language was English. This is a wake-up call for any developer relying solely on a single language or entity-specific analysis.
Let’s dig into how we can catch this sentiment spike using our API. To start, we’ll filter by the English language and focus on the topic of "cloud." Here’s how you can implement that in Python:
import requests
# Define the API endpoint and parameters
url = 'https://api.pulsebit.com/sentiment'
params = {
'topic': 'cloud',
'lang': 'en' # Geographic origin filter
}
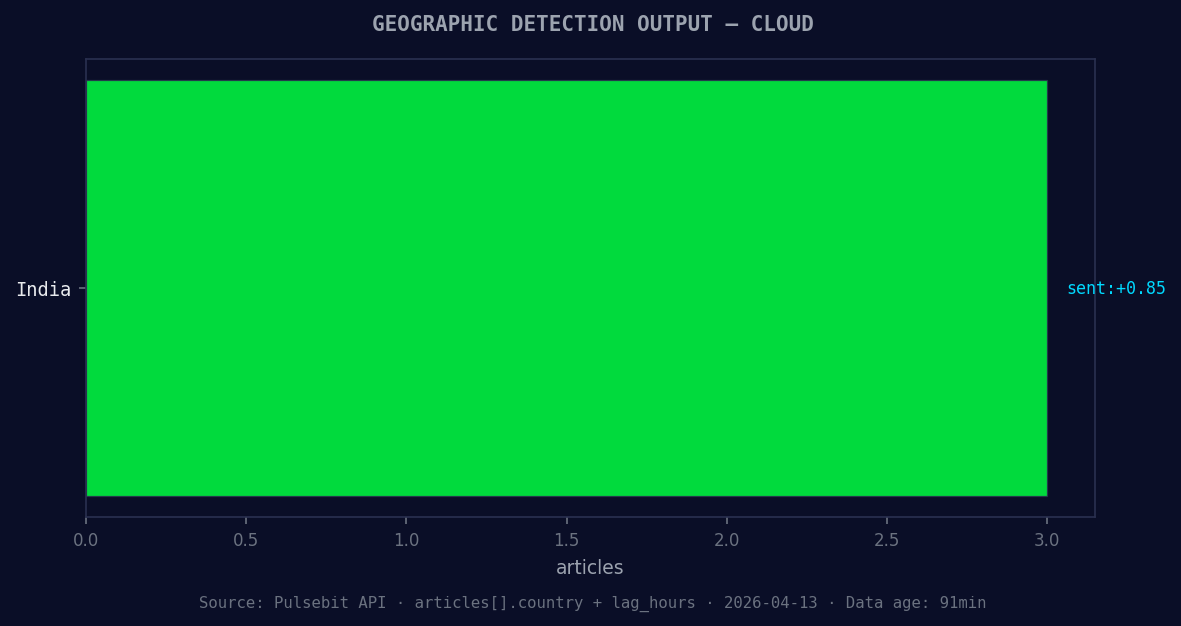
*Geographic detection output for cloud. India leads with 3 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get(url, params=params)
data = response.json()
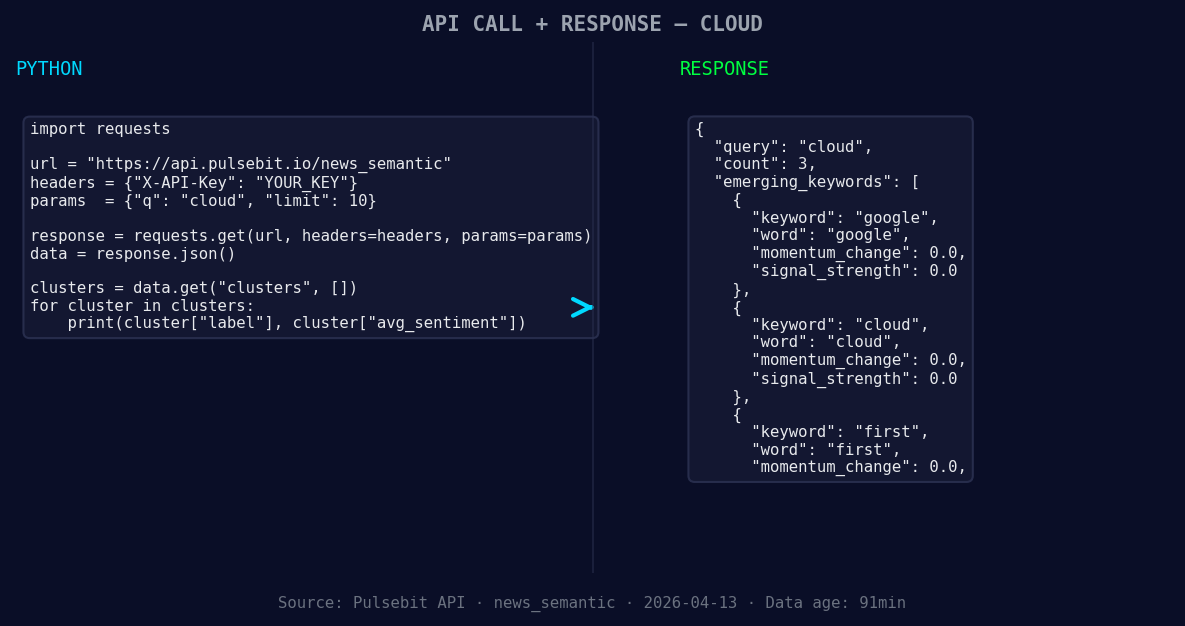
*Left: Python GET /news_semantic call for 'cloud'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Check for a successful response
if response.status_code == 200:
momentum = data['momentum_24h']
score = data['sentiment_score']
confidence = data['confidence']
print(f"Momentum: {momentum}, Score: {score}, Confidence: {confidence}")
else:
print(f"Error: {data['message']}")
Next, we’ll want to run a sentiment analysis on the narrative framing itself. This is crucial for understanding the context around our findings. Using the cluster reason string, we can score its sentiment as follows:
# Define the narrative framing
narrative = "Clustered by shared themes: anthropic, coreweave, cloud, deal, stock."
# Make the sentiment analysis call
response_narrative = requests.post(url, json={"text": narrative})
data_narrative = response_narrative.json()
# Check for a successful response
if response_narrative.status_code == 200:
narrative_sentiment = data_narrative['sentiment_score']
narrative_confidence = data_narrative['confidence']
print(f"Narrative Sentiment: {narrative_sentiment}, Confidence: {narrative_confidence}")
else:
print(f"Error: {data_narrative['message']}")
Now that we have the tools to catch these spikes, here are three specific builds you can implement tonight:
Geo-Filtered Sentiment Alerts: Create an endpoint that triggers an alert when the momentum exceeds a threshold (e.g., +0.1) for topics like "cloud" specifically from English sources. This helps you react swiftly to localized trends.
Meta-Sentiment Dashboard: Build a dashboard that captures and visualizes the sentiment scores of clustered narratives. Use the meta-sentiment loop to provide a contextual overview of the sentiment surrounding themes like "anthropic" and "coreweave," helping you understand the market better.
Forming Gap Insights: Set up a monitoring service that checks for forming gaps, such as discrepancies between mainstream topics (like "anthropic") and emerging trends (like "google" or "first"). If there’s a sentiment score of +0.00 for forming topics, it may indicate potential opportunities for investment or research.
Ready to get started? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes, and before you know it, your pipeline will be much more responsive to sentiment shifts!

Top comments (0)