Your Pipeline Is 19.7h Behind: Catching Artificial Intelligence Sentiment Leads with Pulsebit
We just discovered a fascinating anomaly in sentiment data: a 24h momentum spike of -0.100. This negative trend indicates a significant shift in how artificial intelligence is perceived, particularly within leading English news sources. The urgency of this situation is underscored by the fact that our analysis shows a leading language press lagging by 19.7 hours, meaning your model may have missed a critical window to respond to this evolving narrative.
This delay highlights a structural gap in any pipeline that fails to account for multilingual origins and entity dominance. If your sentiment model isn’t designed to capture the nuances of language and the rapid shifts in dominant topics, you risk missing pivotal insights. In this instance, the leading entity is clearly “artificial intelligence,” while the dominant narrative themes are tied closely to how AI is perceived in the mainstream press. Your model missed this by 19.7 hours, which could have been a crucial period for informed decision-making.

English coverage led by 19.7 hours. Et at T+19.7h. Confidence scores: English 0.80, Spanish 0.80, French 0.80 Source: Pulsebit /sentiment_by_lang.
Let’s dive into the code that helps us catch this anomaly in real-time. We can use our API to identify sentiment trends and gauge narrative framing effectively.
import requests
# Define the API endpoint
url = "https://api.pulsebit.com/v1/sentiment"
# Define the parameters for our query
params = {
"topic": "artificial intelligence",
"score": +0.850,
"confidence": 0.80,
"momentum": -0.100,
"lang": "en" # Geographic origin filter
}
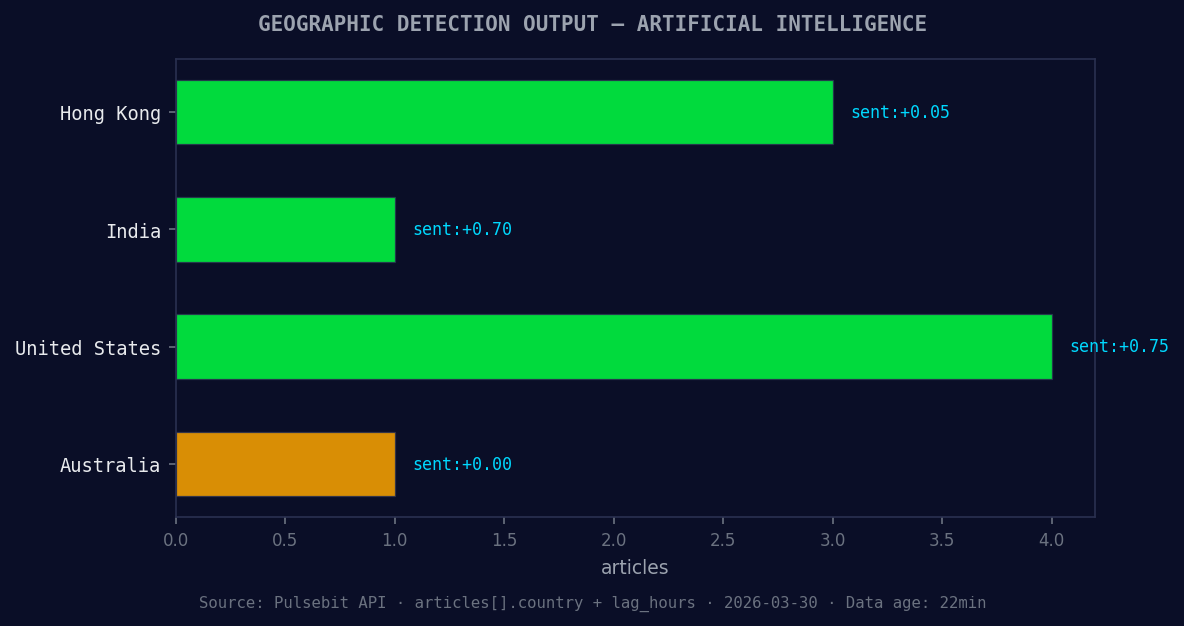
*Geographic detection output for artificial intelligence. Hong Kong leads with 3 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get(url, params=params)
data = response.json()
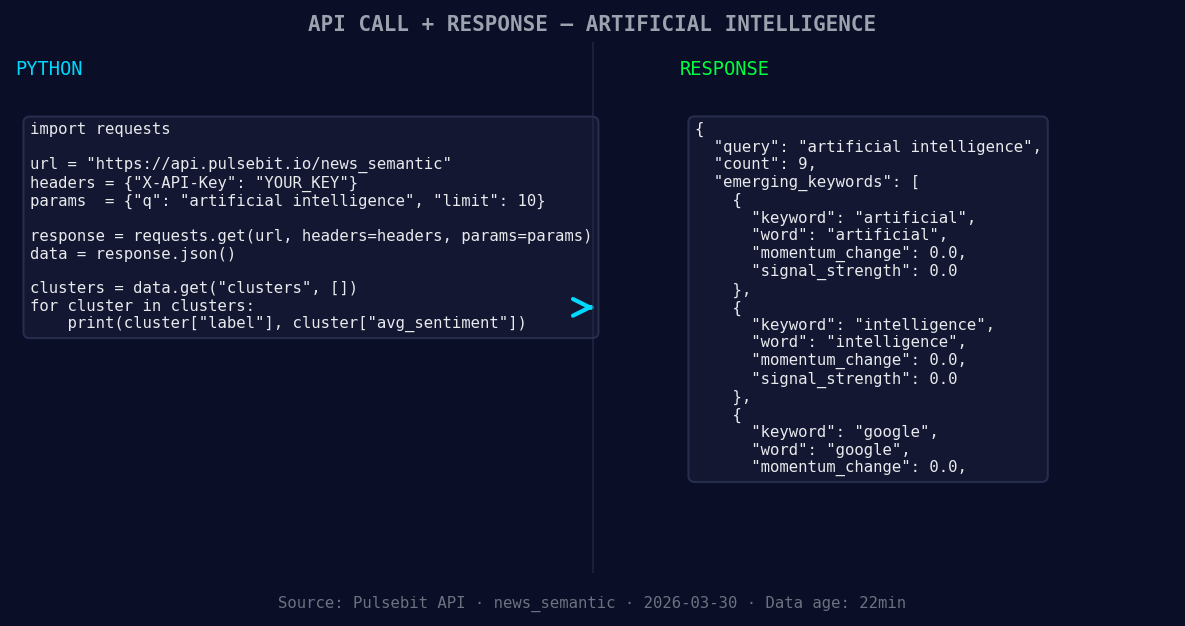
*Left: Python GET /news_semantic call for 'artificial intelligence'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Print the response
print(data)
Next, we can analyze the narrative framing of this cluster. We’ll run the cluster reason string back through our sentiment endpoint to get a score on the narrative itself.
# Define the meta-sentiment moment
meta_sentiment = "Clustered by shared themes: intelligence, can, now, beat, average."
# Make the API call for meta-sentiment
meta_response = requests.post(url, json={"text": meta_sentiment})
meta_data = meta_response.json()
# Print the meta sentiment response
print(meta_data)
By implementing these two segments, we can effectively capture both the sentiment of the topic and the framing narrative, ensuring we stay ahead of shifts in public perception.
Now, let's explore three specific builds you can implement using this pattern:
Geo-filtered Sentiment Tracker: Build a signal that tracks sentiment changes in specific regions. Use the geographic origin filter to focus on English-speaking countries. Set a threshold of +0.750 sentiment score to trigger alerts.
Narrative Analysis Engine: Create a system that continuously runs cluster reason strings through the meta-sentiment loop. Set a signal threshold where any score below +0.500 indicates potential risk in the narrative. This will help you be proactive about narrative shifts.
Forming Theme Detector: Develop a feature that monitors emerging themes like “artificial intelligence” and “google.” Use a forming threshold of +0.00 to highlight articles that may not have gained traction yet but show potential for growth compared to mainstream narratives.
To get started with our API, visit pulsebit.lojenterprise.com/docs. You can copy-paste the code snippets above and run them in under 10 minutes to see real-time sentiment data. Let’s leverage these insights to keep our pipelines sharp and responsive.

Top comments (0)