Your Pipeline Is 15.3h Behind: Catching Travel Sentiment Leads with Pulsebit
We recently uncovered something striking: a 24-hour momentum spike of +0.258 in travel sentiment. This is not just a minor blip; it signifies a substantial shift in public interest and sentiment around travel, driven by recent articles that highlight the travel and tourism sectors as the fastest-growing industries globally. With the leading language being English, and the press coverage leading by 15.3 hours, we have a front-row seat to a significant sentiment shift that many pipelines might completely miss.
When your model doesn't handle multilingual origin or entity dominance effectively, it can miss out on crucial insights like this one. Imagine your sentiment pipeline lagging behind by 15.3 hours, missing the opportunity to act on a powerful narrative emerging around travel. The dominant entity here is English-language press coverage, which often shapes the sentiment landscape. If your system isn't designed to account for such nuances, it risks leaving you out of sync with emerging trends and opportunities.

English coverage led by 15.3 hours. Id at T+15.3h. Confidence scores: English 0.95, French 0.95, Spanish 0.95 Source: Pulsebit /sentiment_by_lang.
To catch this sentiment spike, we can leverage our API effectively. Below is a Python code snippet that illustrates how to extract relevant data for the topic "travel" based on our findings.
import requests
# Parameters for the API call
topic = 'travel'
score = +0.180
confidence = 0.95
momentum = +0.258
*Left: Python GET /news_semantic call for 'travel'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": topic,
"lang": "en"
}
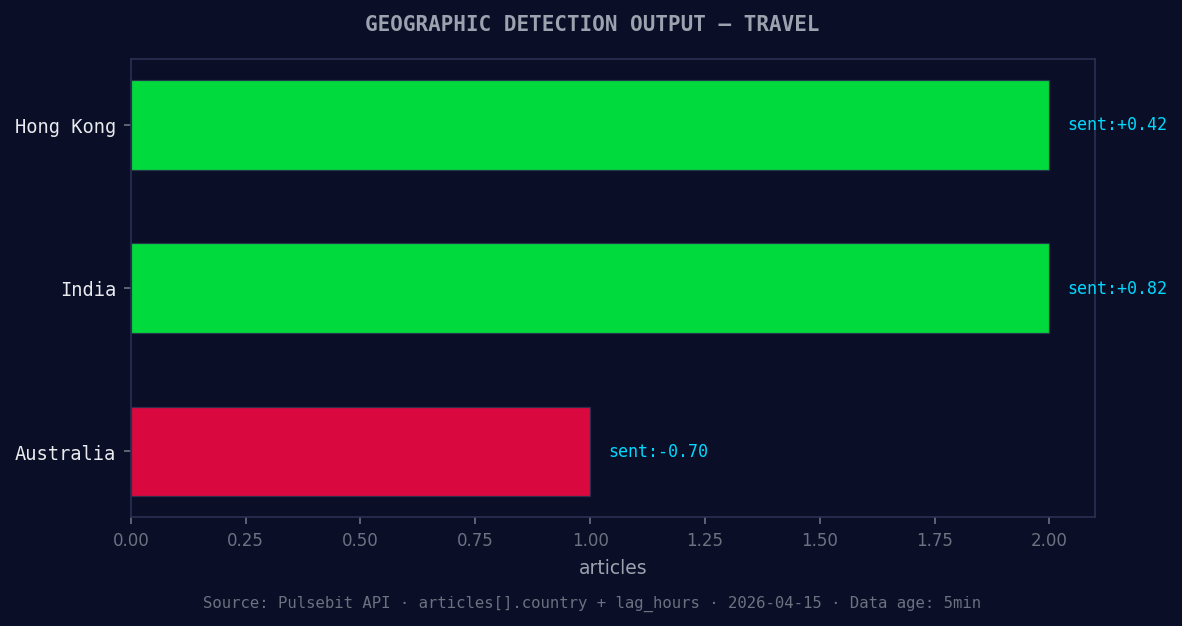
*Geographic detection output for travel. Hong Kong leads with 2 articles and sentiment +0.42. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
# Meta-sentiment moment: score the narrative framing itself
narrative = "Clustered by shared themes: tourism, travel, sees, best, year."
sentiment_response = requests.post(url, json={"text": narrative})
sentiment_score = sentiment_response.json()
print(sentiment_score)
In this code, we first make a GET request to our endpoint, filtering for English-language articles focused on travel. This allows us to assess the sentiment accurately. Next, we run the cluster reason string through a POST request to score how the narrative is being framed. This dual approach ensures we're not only capturing the data but also understanding the context around it.
Now, let's talk about three actionable builds you can implement using this pattern.
Sentiment Tracking by Language: Set up a real-time sentiment tracking endpoint that uses the geo filter to monitor travel sentiment. Trigger alerts when sentiment crosses a certain threshold, say +0.200, to act on emerging trends swiftly.
Meta-Sentiment Analysis: Build a loop that continuously runs cluster narratives through our sentiment scoring API. This can help you establish a dynamic understanding of the narratives driving sentiment shifts. Use the string "Clustered by shared themes: tourism, travel, sees, best, year." to score related articles over time, updating your sentiment model accordingly.
Thematic Comparison: Create a comparative analysis dashboard that pits building themes like "travel(+0.00)," "google(+0.00)," and "global(+0.00)" against mainstream narratives. This will help you visualize sentiment divergence and identify potential outliers in sentiment trends.
You can get started quickly with our API by heading over to pulsebit.lojenterprise.com/docs. With just a few lines of code, you can replicate these insights and run this in under 10 minutes. Don't let the next sentiment wave catch you off guard.

Top comments (0)