Your Pipeline Is 28.8h Behind: Catching Food Sentiment Leads with Pulsebit
We recently detected a 24-hour momentum spike of +0.150 in the food sentiment sector. This anomaly stands out because it indicates a significant shift in sentiment, driven by a leading narrative around Hyderabad chefs innovating beyond traditional biryani, and a focused interest in Telugu micro-cuisines. It’s a clear signal that something new and exciting is brewing in the culinary world, and it’s time to pay attention.
The real challenge here lies in your pipeline's ability to capture such nuanced, multilingual trends. If your model can’t handle this, it missed this spike by a staggering 28.8 hours due to its reliance on English-centric data. You’re potentially losing out on vital insights that could inform your decisions, especially when the leading language is French, which might not even be on your radar.

French coverage led by 28.8 hours. No at T+28.8h. Confidence scores: French 0.85, English 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike effectively, we can utilize our API to filter for French content and analyze the emerging themes. Here’s how to do it in Python:
import requests
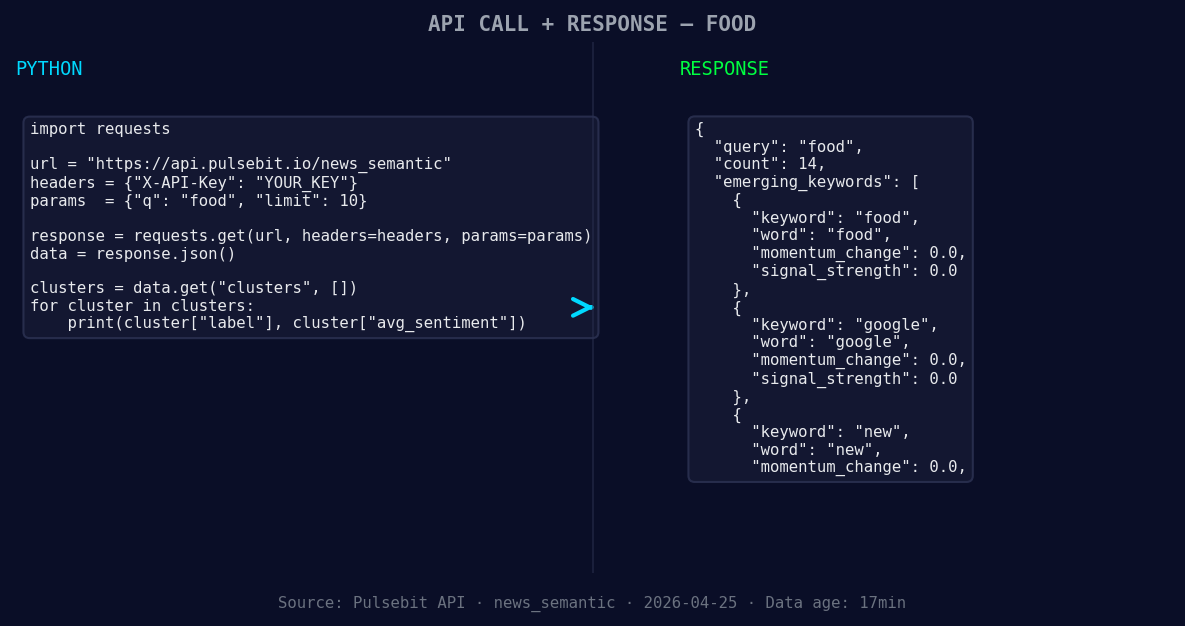
*Left: Python GET /news_semantic call for 'food'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "food",
"lang": "fr" # Filter for French content
}
response = requests.get(url, params=params)
data = response.json()
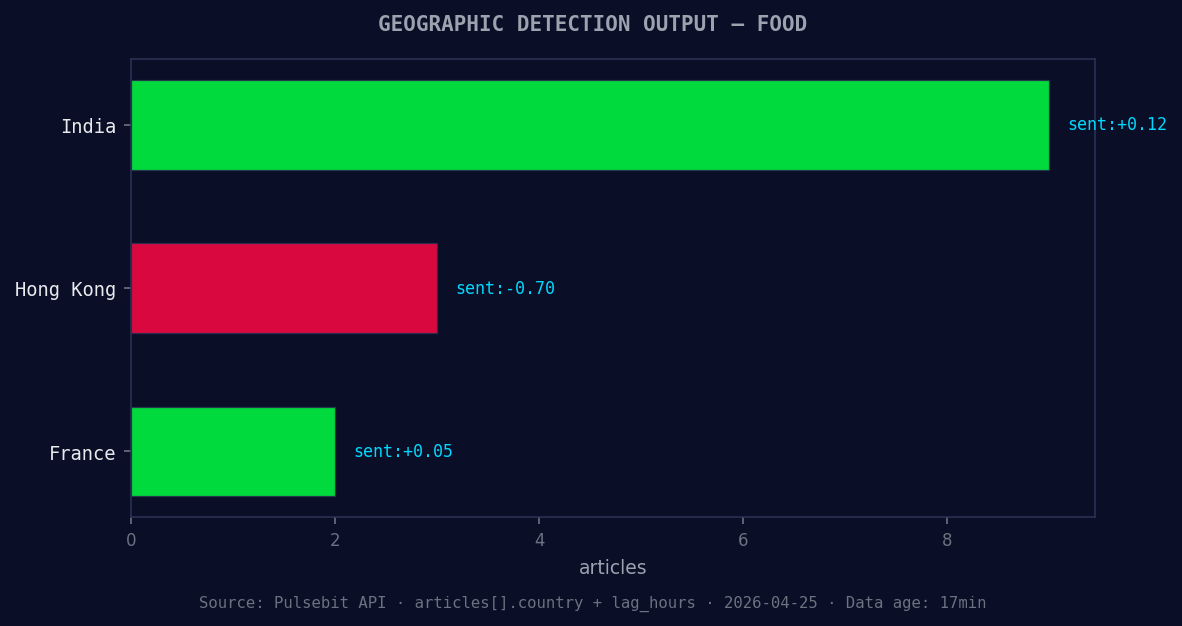
*Geographic detection output for food. India leads with 9 articles and sentiment +0.12. Source: Pulsebit /news_recent geographic fields.*
# Extracting relevant data
momentum = data['momentum_24h']
score = data['sentiment_score']
confidence = data['confidence']
print(f"24h Momentum: {momentum}, Sentiment Score: {score}, Confidence: {confidence}")
# Step 2: Meta-sentiment moment
narrative = "Clustered by shared themes: chefs, telugu, hyderabad, going, beyond."
sentiment_response = requests.post(f"{url}/sentiment", json={"text": narrative})
meta_sentiment = sentiment_response.json()
print(f"Meta Sentiment Score: {meta_sentiment['sentiment_score']}")
In this code, we first filter the data for French content related to food, then we analyze the sentiment of the clustered narrative that describes the emerging themes. This dual approach allows us to catch not just the spike, but also the context around it, which is critical for effective decision-making.
Now, let’s discuss three specific things we can build with this pattern:
Geographic Origin Alerts: Set an alert for any sentiment spike in the food topic specifically for French articles. Use a threshold score of +0.150 to trigger notifications. This ensures you're always on top of emerging trends from key regions.
Meta-Sentiment Analysis Dashboard: Create a dashboard that runs the narrative framing through our sentiment scoring endpoint. This allows us to visualize how the themes of "chefs" and "Telugu" are evolving, and how they compare to mainstream sentiments. Use the input: "Clustered by shared themes: chefs, telugu, hyderabad, going, beyond."
Forming Theme Tracker: Build a tracker that identifies forming themes in food, google, and new. Flag any sentiment shift where the mainstream sentiment diverges from emerging signals. For instance, if the sentiment score for "food" is rising but "chefs" remains flat, that’s a signal you need to investigate further.
To get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run it in under 10 minutes. Don’t let your pipeline lag behind—stay ahead of the trends!

Top comments (0)