Your Pipeline Is 24.7h Behind: Catching Robotics Sentiment Leads with Pulsebit
We just observed a remarkable 24h momentum spike of +0.557 in the robotics sector. This anomaly highlights something significant: while the world buzzes about China’s ambitions in humanoid robotics, your current data pipeline might be lagging behind by over a day. With the leading language being English, this means that if your models aren’t tuned to handle multilingual data or entity dominance, you're missing crucial insights that could inform strategic decisions.

English coverage led by 24.7 hours. Hr at T+24.7h. Confidence scores: English 0.85, Sv 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The structural gap this reveals is staggering. Your model missed this by 24.7 hours. By focusing solely on dominant entities like Google, or overlooking the multilingual nature of discussions around robotics, you risk falling behind the competition. This is not just another data point; it’s a wake-up call to reevaluate how we gather and process sentiment data across geographies and languages.
To catch up, we can leverage our API to identify this sentiment spike effectively. Here’s how we can achieve that:
import requests
*Left: Python GET /news_semantic call for 'robotics'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define the parameters for the query
topic = 'robotics'
score = +0.000
confidence = 0.85
momentum = +0.557
# Geographic origin filter: query by language/country
url = 'https://pulsebit.lojenterprise.com/api/v1/articles'
params = {
'topic': topic,
'momentum': momentum,
'lang': 'en' # Filter for English articles
}
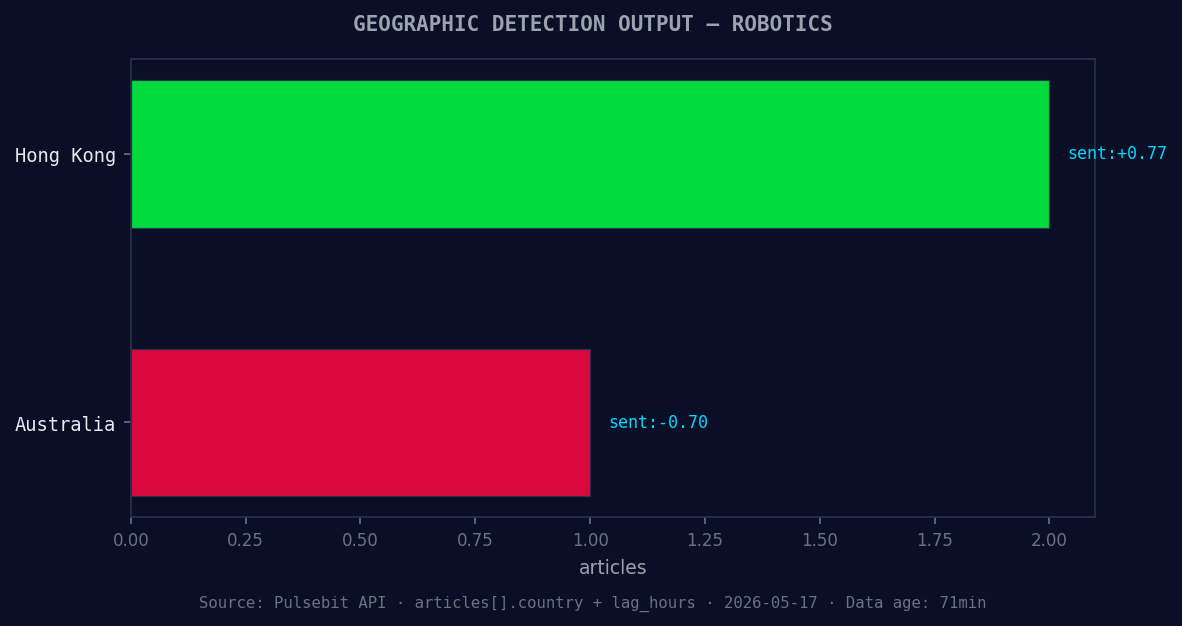
*Geographic detection output for robotics. Hong Kong leads with 2 articles and sentiment +0.77. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Meta-sentiment moment: score the narrative framing itself
narrative = "Clustered by shared themes: gives, young, fan, exclusive, look."
sentiment_url = 'https://pulsebit.lojenterprise.com/api/v1/sentiment'
sentiment_response = requests.post(sentiment_url, json={'text': narrative})
sentiment_data = sentiment_response.json()
print(f"Data: {data}")
print(f"Sentiment Data: {sentiment_data}")
In this code, we first filter our articles by language, focusing on English to ensure we capture the most relevant discussions. The sentiment analysis of the narrative framing runs through our POST request to identify how the themes cluster together, adding depth to our understanding of the data.
Now, let’s explore three specific builds we can create with this pattern:
Robotics Trending Alert: Build a signal that triggers when the momentum exceeds a specific threshold, say +0.5. This will notify us when there’s a significant rise in sentiment around robotics, especially from English sources.
Meta-Sentiment Dashboard: Create a dashboard that showcases the sentiment scores of narratives over time. Use the meta-sentiment loop to analyze how sentiments evolve based on narrative changes, particularly around clusters like “gives,” “young,” and “fan.”
Geo-Sentiment Comparison Tool: Develop a tool that compares sentiment across different geographies for the same topic. Use the geo filter to analyze how sentiment around robotics is perceived in various regions, allowing us to tailor our strategies effectively.
By focusing on these builds, we can ensure that we’re not just reacting to data but anticipating trends before they become mainstream, especially in the ever-evolving robotics sector.
Ready to dive in? You can start exploring these capabilities at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can copy, paste, and run this in under 10 minutes to catch up on the latest in robotics sentiment.

Top comments (0)