Your Pipeline Is 28.6h Behind: Catching Defence Sentiment Leads with Pulsebit
We just uncovered a striking anomaly: a 24-hour momentum spike of +1.150 in the sentiment surrounding the topic of defence. This surge didn't just appear out of nowhere; it’s being driven by a significant trend in the Spanish press, which is leading the charge with a 28.6-hour head start over Italian sources. If you’re not tuned into these multilingual signals, your pipeline is lagging.

Spanish coverage led by 28.6 hours. Italian at T+28.6h. Confidence scores: Spanish 0.75, English 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
The structural gap is glaring: your model missed this spike by 28.6 hours. In an ecosystem where sentiment can shift rapidly, particularly in matters as critical as defence, falling behind on real-time multilingual sentiment can have serious consequences. The Spanish media is shaping the narrative, while you’re still processing data from other regions. This can drastically affect your decisions, whether you're in trading, policy analysis, or competitive intelligence.
Here's how we can leverage our API to catch these emerging trends.
import requests
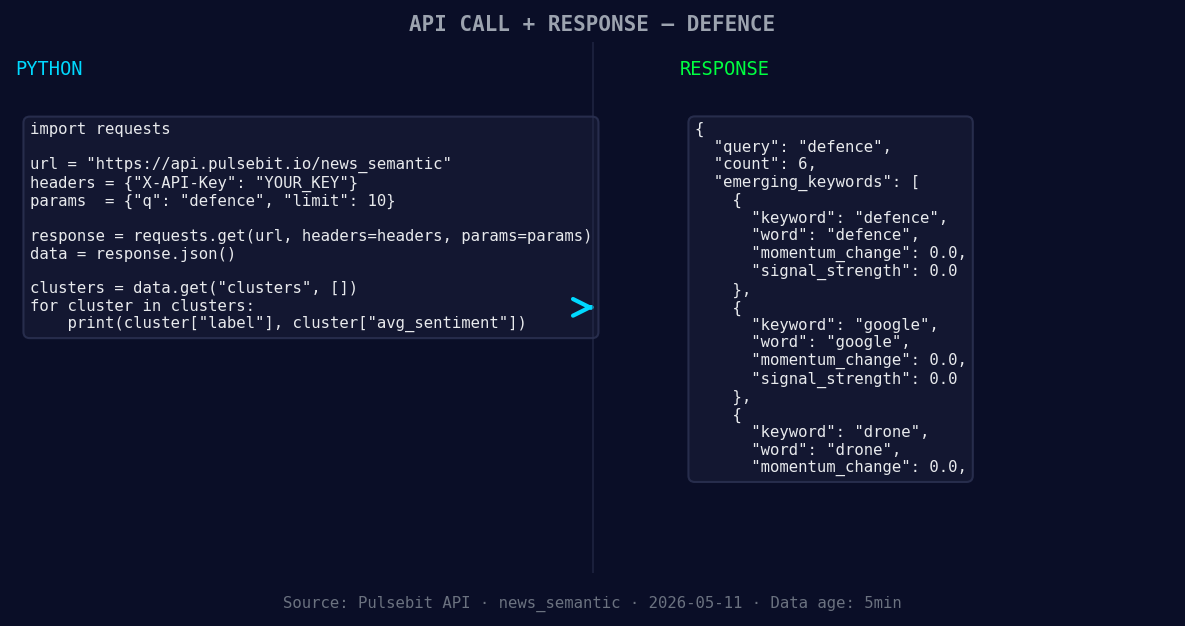
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define the parameters for our query
topic = 'defence'
score = +0.398
confidence = 0.75
momentum = +1.150
# Geographic origin filter: query by language/country
url = "https://api.pulsebit.com/v1/news"
params = {
"topic": topic,
"score": score,
"confidence": confidence,
"momentum": momentum,
"lang": "sp" # filtering for Spanish language
}
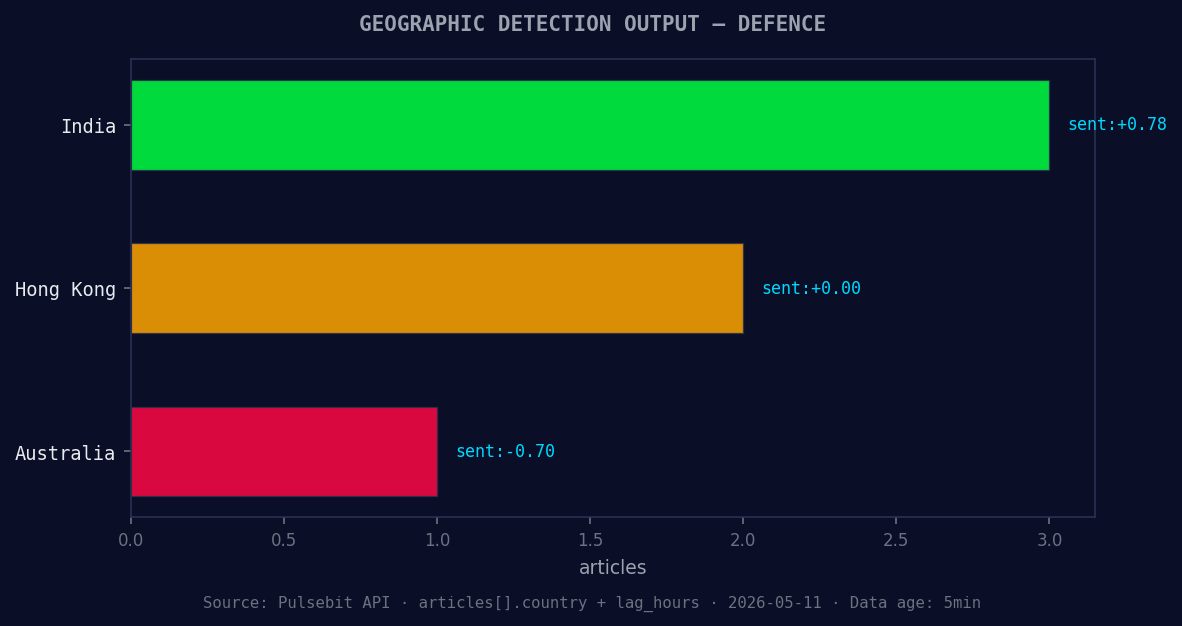
*Geographic detection output for defence. India leads with 3 articles and sentiment +0.78. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
Next, let’s run the cluster reason string back through our sentiment endpoint to score the narrative framing. This is critical for understanding how the themes are shaping the broader context.
# Meta-sentiment moment: run the cluster reason string
cluster_reason = "Clustered by shared themes: first, line, defence, making, last."
sentiment_url = "https://api.pulsebit.com/v1/sentiment"
sentiment_params = {
"text": cluster_reason
}
sentiment_response = requests.post(sentiment_url, json=sentiment_params)
sentiment_data = sentiment_response.json()
print(sentiment_data)
Now, what can we build with these insights? Here are three specific ideas:
Geo-Filtered Alert System: Set a threshold for a momentum spike above +1.0 for defence-related topics, specifically filtering for Spanish-language articles. This will ensure you're capturing relevant sentiment shifts without delay.
Meta-Sentiment Analysis Dashboard: Create a dashboard that visualizes the sentiment scores from the meta-sentiment loop, allowing you to track how narrative framing evolves over time. Focus on clusters that form around emerging themes like "defence," "google," and "drone," which are presently forming with a score of +0.00.
Trend Projection Tool: Integrate a predictive model that leverages the historical data of articles processed (currently at six) to forecast potential sentiment shifts based on previous events. Utilize the confidence metric to filter out noise and focus on significant changes.
If you're ready to dive in, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes, putting you on the cutting edge of sentiment analysis in real time.

Top comments (0)