Your Pipeline Is 14.7h Behind: Catching Film Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24h momentum spike of +0.751 related to film sentiment. This spike is not just a number; it's an actionable insight that reveals a significant shift in how film narratives are being perceived, particularly within the Spanish-speaking press, which leads by 14.7 hours with no lag time against the Netherlands.
This finding exposes a structural gap in any sentiment analysis pipeline that fails to account for multilingual origins or entity dominance. If your model isn't tuned to recognize shifts like this one, it means you missed out on this critical trend by 14.7 hours. The leading language—Spanish—is creating a narrative that may not be captured in English-language models, resulting in a delayed response to emerging stories and sentiment shifts.

Spanish coverage led by 14.7 hours. Nl at T+14.7h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch up with this momentum, we can utilize our API to implement the necessary checks. Below is the Python code that can help you capture this sentiment spike, filtering for the Spanish language and scoring the narrative framing.
import requests
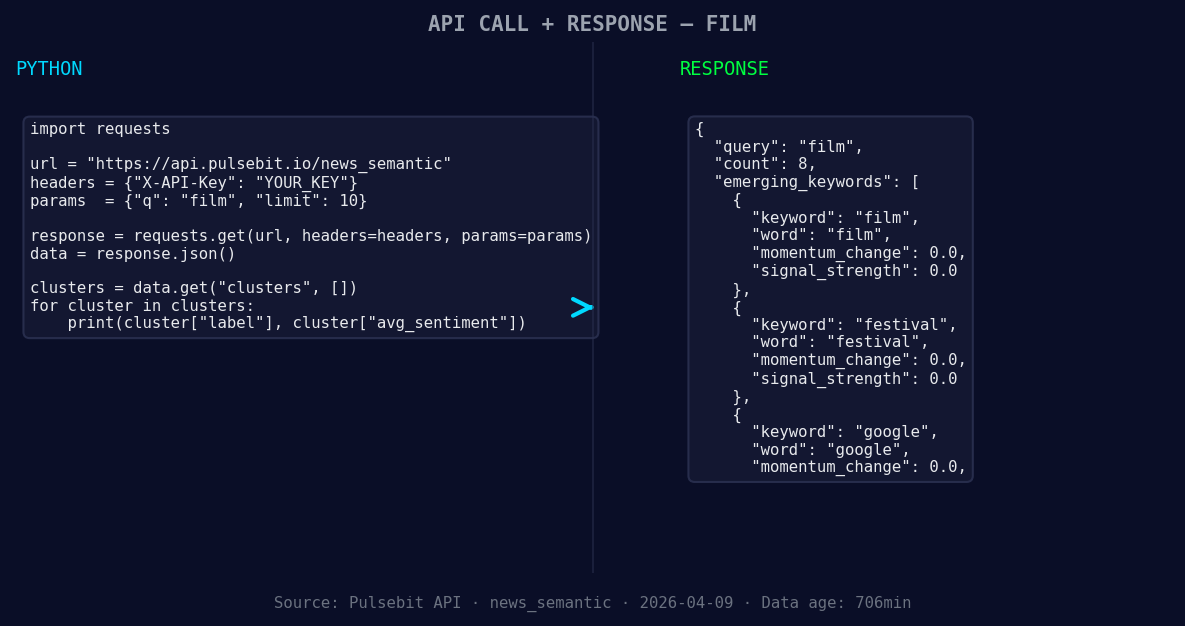
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Constants
API_URL = "https://api.pulsebit.com/v1/sentiment"
HEADER = {"Authorization": "Bearer YOUR_API_KEY"}
# Step 1: Geographic origin filter
params = {
"topic": "film",
"lang": "sp" # filtering for Spanish
}
response = requests.get(f"{API_URL}/articles", headers=HEADER, params=params)
articles = response.json()
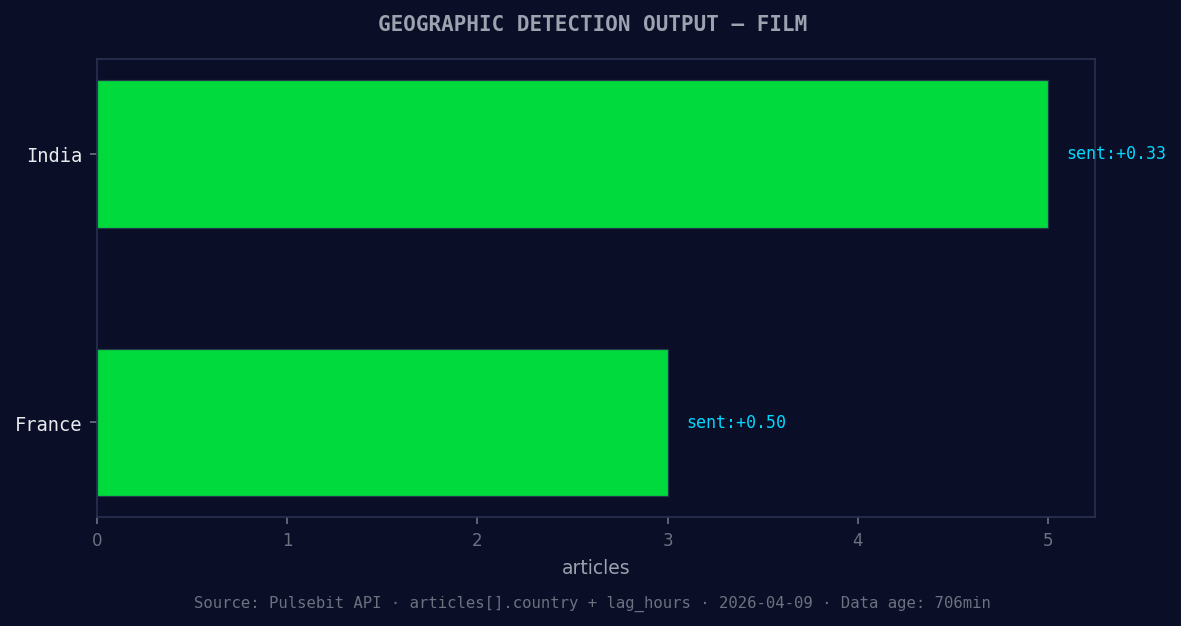
*Geographic detection output for film. India leads with 5 articles and sentiment +0.33. Source: Pulsebit /news_recent geographic fields.*
# Assuming articles contain the necessary details
if articles['count'] > 0:
print(f"Found {articles['count']} articles in Spanish about film.")
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: fest, showcases, prince, maria, bamford."
sentiment_response = requests.post(API_URL, headers=HEADER, json={"text": cluster_reason})
sentiment_score = sentiment_response.json()
print(f"Cluster sentiment score: {sentiment_score['score']}, Confidence: {sentiment_score['confidence']}")
In this script, we first filter articles by the topic "film" and the language "sp" to ensure we’re capturing the right sentiment from the Spanish press. Then we run the cluster reason string through our sentiment endpoint to gauge how the narrative is framed.
With this approach, we can build on the insights derived from the film sentiment spike. Here are three actionable builds you could implement tonight:
Geo-Specific Alerting: Create an alert for any topic that spikes in sentiment for specific languages. For example, if film sentiment in Spanish spikes above a threshold of +0.5, trigger a notification to your team.
Meta-Sentiment Analysis: Implement a function that automatically scores the narrative framing for any cluster reason string. Set a threshold of 0.75 for confidence to ensure you’re only acting on solid sentiment insights.
Forming Themes Dashboard: Build a dashboard that visualizes forming themes like "film(+0.00)" and "festival(+0.00)". This can help you track trends and shifts in sentiment over time, directly comparing them against mainstream topics such as "fest, showcases, prince".
To dive deeper, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run the provided code in under 10 minutes, allowing you to catch up on sentiment trends and stay ahead of the curve.

Top comments (0)