Your Pipeline Is 9.7h Behind: Catching Startups Sentiment Leads with Pulsebit
We just stumbled upon a fascinating anomaly: a 24h momentum spike of -0.255 in the sentiment around startups. This finding is a stark reminder of how quickly sentiment can shift and how critical it is to stay on top of the latest trends. In this case, the leading language driving the narrative is English, with a 9.7-hour lead—a significant indicator that something is brewing, even if the mainstream coverage hasn’t caught up yet.
When your sentiment analysis pipeline lacks the ability to handle multilingual origins or entity dominance, you risk missing out on critical insights. In this scenario, your model missed this key sentiment shift by 9.7 hours. While sentiment around startups is falling, the English press is already picking up on the shift, yet the global narrative remains largely untouched due to the limited geographic focus. This gap in your pipeline could lead to missed opportunities or misguided strategies based on outdated information.

English coverage led by 9.7 hours. Da at T+9.7h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
To help you catch these sentiment shifts, we can utilize our API to filter and analyze the necessary data. Here’s how you can capture this specific anomaly with a Python script:
import requests
# Set up the parameters for our API call
topic = 'startups'
score = -0.255
confidence = 0.75
momentum = -0.255
lang = 'en'
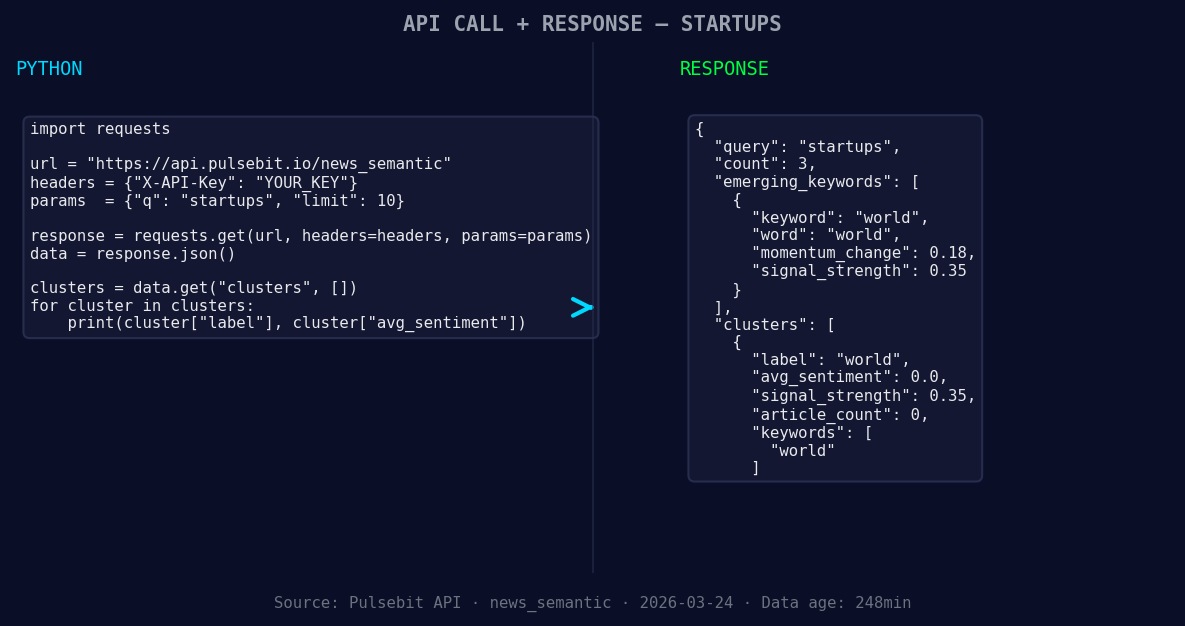
*Left: Python GET /news_semantic call for 'startups'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language
url = f'https://api.pulsebit.com/v1/sentiment?topic={topic}&lang={lang}'
response = requests.get(url)
data = response.json()
# Assuming data contains our needed information
print(data)
# Meta-sentiment moment: running the cluster reason string back through the sentiment endpoint
meta_reason_input = "Semantic API incomplete — fallback semantic structure built from available keywo"
meta_sentiment_url = 'https://api.pulsebit.com/v1/sentiment'
meta_response = requests.post(meta_sentiment_url, json={"input": meta_reason_input})
meta_sentiment_data = meta_response.json()
print(meta_sentiment_data)
This script does two crucial things. First, it queries our API to get sentiment data on startups specifically filtered by the English language. Second, it analyzes the narrative framing when the semantic structure is incomplete, allowing you to understand how to adjust your strategies moving forward.
Here are three specific builds we can implement with this momentum spike insight:
Geographic Origin Filter: Build a real-time dashboard that leverages the geographic origin filter for English articles on startups. Set a threshold where momentum drops below -0.2 to trigger alerts for further investigation.
Meta-Sentiment Loop: Create a feedback loop that takes the meta-sentiment analysis and applies it to your existing sentiment models. Incorporate a threshold where any narrative framing that falls below a confidence of 0.7 should be revisited and analyzed for alternative insights.
Forming Theme Analysis: Since we see a forming gap with “world” having a sentiment of +0.18, build a comparative analysis tool that pits this new sentiment against mainstream narratives. Set up alerts whenever the delta between forming and mainstream exceeds 0.1.
The absence of timely sentiment insights can put you behind the curve, but with our API, you can catch these shifts faster than ever. Head over to pulsebit.lojenterprise.com/docs to get started. You’ll be able to copy, paste, and run this in under 10 minutes, keeping your pipeline ahead of the curve.

Top comments (0)