Your Pipeline Is 7.7h Behind: Catching Startups Sentiment Leads with Pulsebit
We recently identified a striking anomaly: a 24h momentum spike of -0.255 related to startups. This negative momentum suggests a significant shift in sentiment that could impact investment decisions and market strategies. The leading source of information was the Spanish press, which lags behind the dominant narrative by 7.7 hours. This time gap is something we can’t afford to overlook.
When your pipeline doesn’t account for multilingual origins or entity dominance, you risk missing critical sentiment shifts. In this case, your model missed a key insight by 7.7 hours, all because it didn't process the Spanish-language articles that had begun to frame the narrative surrounding startups. If you’re relying solely on English-language sources, you could be blindsided by emerging trends or shifts that are uniquely captured in other languages.

Spanish coverage led by 7.7 hours. Da at T+7.7h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s how we can catch this anomaly and harness it in Python using our API:
import requests
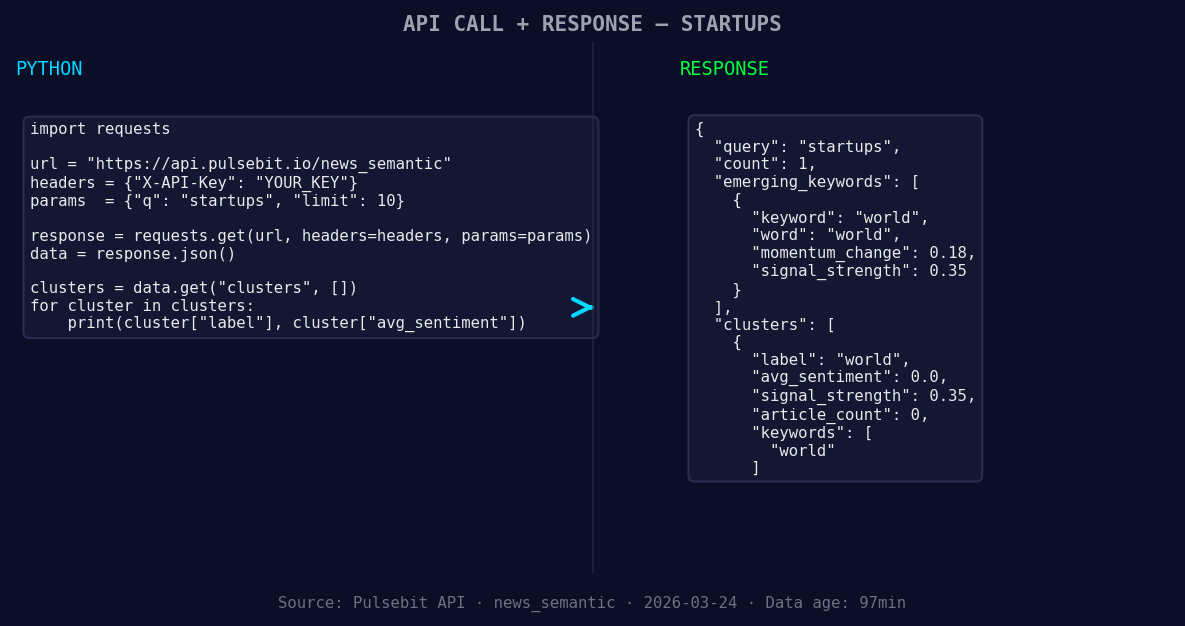
*Left: Python GET /news_semantic call for 'startups'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define your parameters
topic = 'startups'
score = -0.255
confidence = 0.85
momentum = -0.255
# Step 1: Geographic origin filter
url = 'https://pulsebit.lojenterprise.com/api/v1/articles'
params = {
"topic": topic,
"lang": "sp" # Spanish language filter
}
response = requests.get(url, params=params)
data = response.json()
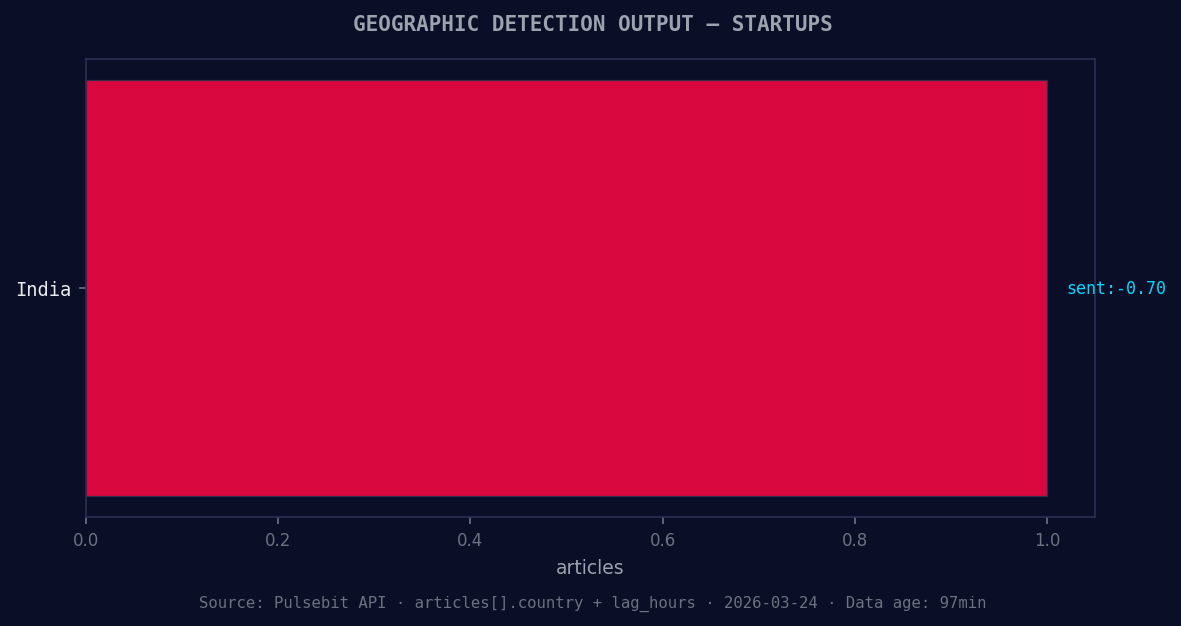
*Geographic detection output for startups. India leads with 1 articles and sentiment -0.70. Source: Pulsebit /news_recent geographic fields.*
# Print the retrieved data
print(data)
# Step 2: Meta-sentiment moment
meta_sentiment_url = 'https://pulsebit.lojenterprise.com/api/v1/sentiment'
meta_input = {
"text": "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
}
meta_sentiment_response = requests.post(meta_sentiment_url, json=meta_input)
meta_sentiment_data = meta_sentiment_response.json()
# Print the meta sentiment result
print(meta_sentiment_data)
In the above code, we first filter articles related to the topic 'startups' specifically from the Spanish language. This allows us to capture the unique sentiment emerging from the Spanish press. Next, we run the meta-sentiment analysis on the narrative framing itself, scoring it for how it might shape or influence perceptions. This dual approach ensures we're not just reacting to raw sentiment but understanding its context and evolution.
Here are three specific builds we can implement tonight based on this insight:
Signal Detection with Geo Filter: Build a detection system that alerts you when the sentiment score for 'startups' drops below -0.3 in the Spanish press. Use the geographic origin filter to ensure you're only capturing relevant data.
Meta-Sentiment Loop for Narrative Insights: Create a dashboard that visualizes the meta-sentiment scores of articles that cite the reason "Semantic API incomplete — fallback semantic structure built from available keywords." This helps you understand how incomplete semantic analysis can distort public perception.
Forming Themes Analysis: Implement a clustering algorithm that continually monitors the forming theme of 'world' and compares it against mainstream narratives. This will allow you to catch early signals of sentiment shifts, like the +0.18 forming sentiment against the mainstream 'world' narrative.
If you’re ready to harness these insights, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and run it in under 10 minutes to start capturing these critical trends. Don't let your pipeline fall behind—stay ahead of the curve.

Top comments (0)