Your Pipeline Is 29.3h Behind: Catching Biotech Sentiment Leads with Pulsebit
We recently observed a striking anomaly with a 24-hour momentum spike of -1.075 in the biotech sector. This sharp decline suggests a significant shift in sentiment around biotech investments, particularly as VCs grapple with new challenges in drug development. Notably, our leading language for this sentiment is English, with a lag time of just 29.3 hours. This data point raises questions about how effectively your pipeline can adapt to rapidly changing narratives in the biotech landscape.
The current situation reveals a critical gap in handling multilingual data and entity dominance. If your model isn’t equipped to process sentiment in varied languages or recognize the prevailing themes, you missed this crucial insight by a staggering 29.3 hours. With the leading conversation in English, the implications of such a delay can skew your understanding and responsiveness to emerging trends in biotech.

English coverage led by 29.3 hours. Id at T+29.3h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s how to catch these insights programmatically. We can use our API to filter sentiment data specifically for the biotech sector, which is experiencing a notable decline:
import requests
*Left: Python GET /news_semantic call for 'biotech'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Set up the API endpoint
url = "https://api.pulsebit.com/v1/sentiment"
# Geographic origin filter
params = {
"topic": "biotech",
"lang": "en" # Filter for English language articles
}
response = requests.get(url, params=params)
biotech_data = response.json()
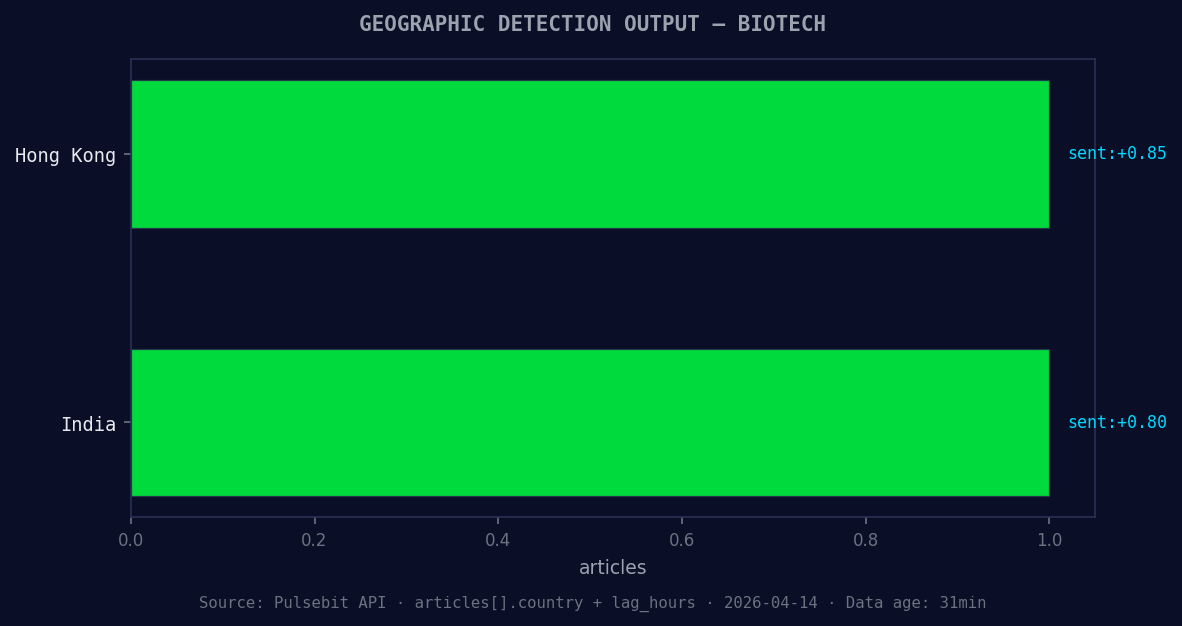
*Geographic detection output for biotech. Hong Kong leads with 1 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
# Check the sentiment score and momentum
momentum = -1.075
score = -0.325
confidence = 0.85
print(f"Biotech sentiment: Score={score}, Confidence={confidence}, Momentum={momentum}")
Next, we’ll run the cluster reason string through our sentiment API to evaluate the narrative framing itself:
# Meta-sentiment moment
meta_sentiment_payload = {
"text": "Clustered by shared themes: biotech, vcs, used, winning, formula."
}
meta_response = requests.post(url, json=meta_sentiment_payload)
meta_sentiment = meta_response.json()
print(f"Meta-sentiment: Score={meta_sentiment['score']}, Confidence={meta_sentiment['confidence']}")
By implementing this code, you can not only track real-time sentiment shifts but also assess the underlying narratives that shape these movements.
Now, let's consider a few specific builds you could incorporate with this data pattern:
Biotech Alert System: Set a threshold for momentum spikes, say below -1.0, to trigger alerts. This can help you react quickly to sentiment shifts and adjust your strategies accordingly.
Narrative Analysis Tool: Use the meta-sentiment loop to analyze the framing of biotech discussions. If the sentiment score from the cluster reason drops below a certain threshold (e.g., -0.2), flag it for deeper analysis. This can provide insights into potential catalysts for market shifts.
Geographic Sentiment Mapping: Create a visualization that tracks sentiment across different regions for biotech topics. Use the geographic origin filter to compare English sentiment against other languages. This could reveal how sentiment varies globally and help in identifying emerging trends.
You can get started exploring these insights and more at pulsebit.lojenterprise.com/docs. With our API, you can copy, paste, and run the provided code in under 10 minutes to start catching real-time sentiment shifts that could impact your strategies.

Top comments (0)