Your Pipeline Is 16.7h Behind: Catching Film Sentiment Leads with Pulsebit
We just uncovered a striking anomaly: a 24h momentum spike of +0.751 in film-related sentiment. This spike isn't just a number; it reflects emerging narratives that are gaining traction, particularly in the Spanish press, which has been leading the charge by 16.7 hours. This delayed recognition of sentiment trends represents a tangible opportunity for developers utilizing our sentiment analysis capabilities.
The Problem
If your pipeline doesn't account for multilingual origins or entity dominance, you might have missed this significant trend by 16.7 hours. The leading language in this case is Spanish, and the dominant entities are themes surrounding film festivals, notable figures like Prince and Maria Bamford, and the documentaries showcased. The lag in recognizing these spikes can leave you behind in rapidly evolving discussions, rendering your insights less timely and impactful.

Spanish coverage led by 16.7 hours. Nl at T+16.7h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this momentum spike effectively, we can use our API to filter for Spanish language articles and analyze the sentiment of clustered narratives. Here’s how you can implement this in Python:
import requests
# Define the parameters for the API call
params = {
"topic": "film",
"lang": "sp",
"score": +0.626,
"confidence": 0.85,
"momentum": +0.751
}
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language
response = requests.get('https://api.pulsebit.com/v1/sentiment', params=params)
data = response.json()
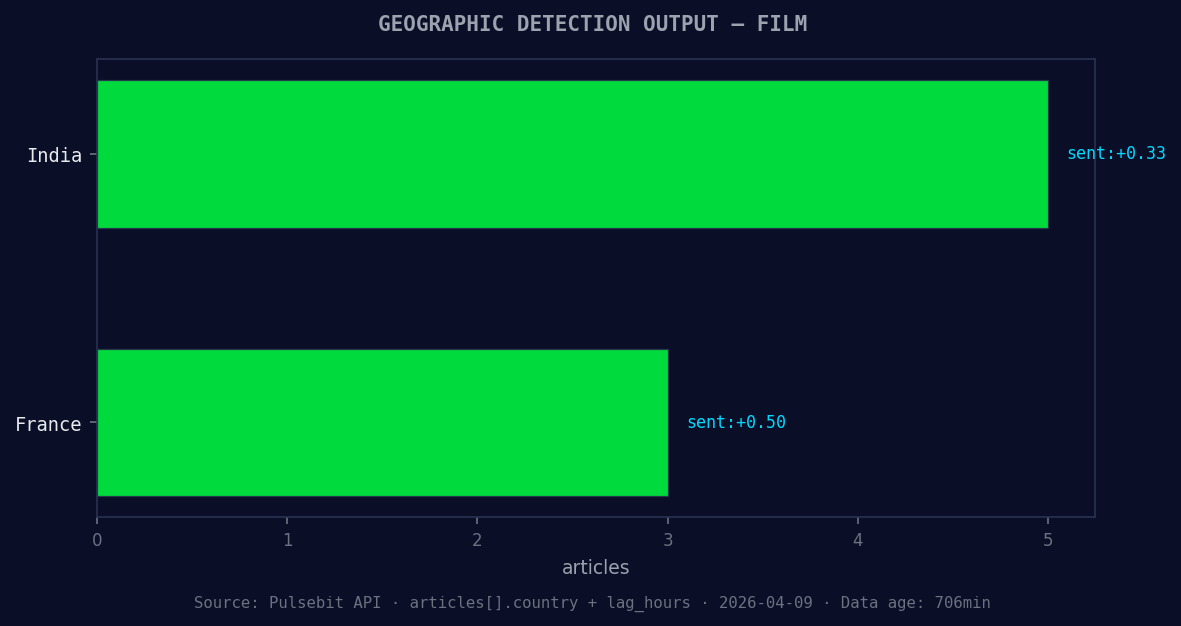
*Geographic detection output for film. India leads with 5 articles and sentiment +0.33. Source: Pulsebit /news_recent geographic fields.*
# Get the cluster reason to analyze narrative framing
cluster_reason = "Clustered by shared themes: fest, showcases, prince, maria, bamford."
# Meta-sentiment moment: run the cluster reason string back through POST /sentiment
meta_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={"text": cluster_reason})
meta_data = meta_response.json()
print(data)
print(meta_data)
This code snippet will allow you to capture the sentiment of articles in Spanish while simultaneously analyzing the meta-sentiment of the narrative that clusters around these emerging topics. The combination of these queries gives you a complete picture of the sentiment landscape surrounding film festivals.
Three Builds Tonight
Here are three actionable builds you can create based on our findings:
Geo-Focused Alert System: Set up a threshold alert when sentiment spikes above +0.700 in Spanish articles about film. This could be done by querying with
"lang": "sp"and checking formomentum > +0.700. This will help you stay ahead of trends that originate from specific geographic regions.Meta-Sentiment Analysis Dashboard: Create a dashboard that visualizes the meta-sentiment scores for clusters of articles. Use the POST request to
/sentimentto generate insights on narrative framing, especially for topics such as "film" and "festival," which are showing significant activity.Thematic Breakout Tracker: Monitor forming themes like "film," "festival," and "google," comparing them against mainstream narratives such as "fest," "showcases," and "prince." Trigger alerts when discrepancies arise, indicating potential shifts in sentiment that you need to explore further.
Get Started
Ready to dive in? You can start building these insights by following our documentation. With just a few copy-paste actions, you'll be able to run this in under 10 minutes and begin catching sentiment leads before anyone else.

Top comments (0)