Your Pipeline Is 24.6h Behind: Catching Regulation Sentiment Leads with Pulsebit
We recently stumbled upon a striking anomaly in our sentiment data: a 24h momentum spike of -0.565. This value reflects a significant drop in sentiment surrounding the topic of regulation. This spike is particularly noteworthy as it reveals a growing tension in global conversations about regulation, which is often reflected in varying degrees by the leading languages of discourse.
But here’s the kicker: your model missed this by a staggering 24.6 hours. The dominant sentiment is coming from English sources, while the Italian press is lagging behind. If you're only processing data from one language or not accounting for multi-lingual dynamics, you're leaving critical insights on the table.
Let’s dive into how we can catch this momentum spike programmatically. To do this, we need to tap into our API to filter for English language articles and analyze the sentiment surrounding regulation. Here’s a Python snippet that does just that:
import requests
*Left: Python GET /news_semantic call for 'regulation'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Define your parameters
topic = 'regulation'
score = -0.565
confidence = 0.85
momentum = -0.565
# Geographic origin filter: query by language/country
response = requests.get(
'https://pulsebit.api/sentiment',
params={
'topic': topic,
'lang': 'en',
'score': score,
'confidence': confidence
}
)
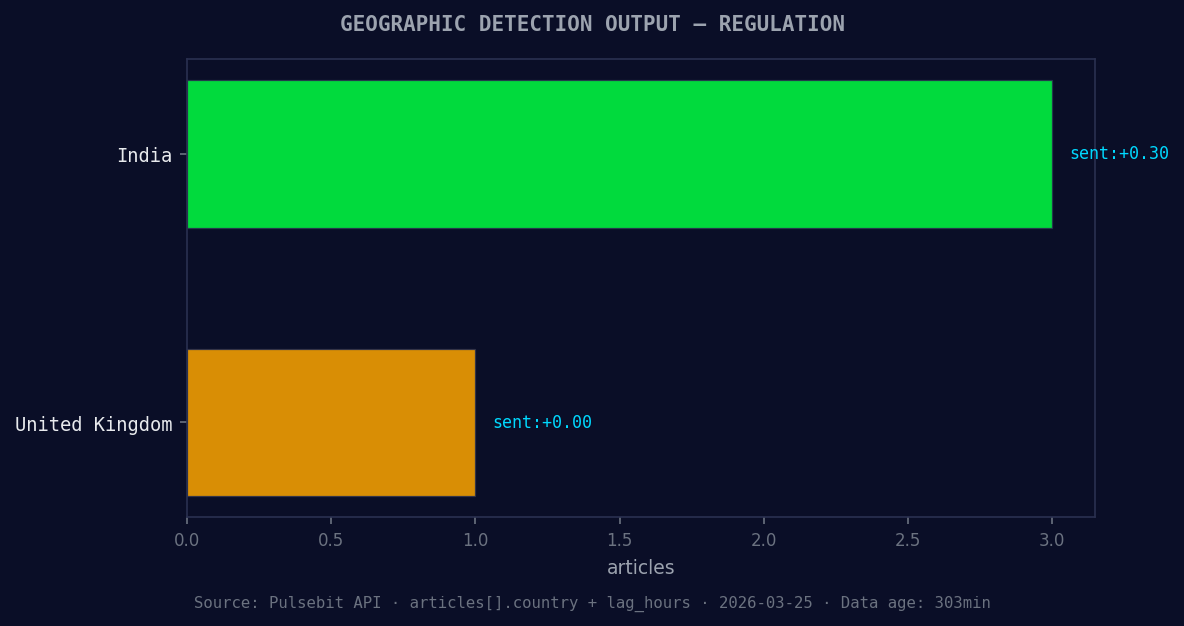
*Geographic detection output for regulation. India leads with 3 articles and sentiment +0.30. Source: Pulsebit /news_recent geographic fields.*
# Check if the request was successful
if response.status_code == 200:
print("Data fetched successfully!")
data = response.json()
else:
print("Failed to fetch data:", response.status_code)
# Meta-sentiment moment
meta_response = requests.post(
'https://pulsebit.api/sentiment',
json={
'input': "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
}
)
# Display meta-sentiment result
if meta_response.status_code == 200:
meta_data = meta_response.json()
print("Meta-sentiment score:", meta_data['sentiment_score'])
else:
print("Failed to fetch meta-sentiment:", meta_response.status_code)
Here, the first part of the code filters articles by language, specifically English, to focus on the most relevant discussions. The second part evaluates the narrative framing of our anomaly by analyzing the meta-sentiment, allowing us to understand the context behind the spike in regulation sentiment.
Now that we have this data, let’s discuss three practical applications we can build using this pattern:
Geo-Filtered Alerts: Set up a real-time alert system using the geographic origin filter. Whenever sentiment drops below a threshold (e.g., -0.5), you get notified about potential regulatory shifts in English-language articles.
Meta-Sentiment Analysis: Create a dashboard that visualizes meta-sentiment scores for key phrases forming around the topics of "world" (+0.18) and "environment" (+0.17). This will help you gauge the overall sentiment trends and identify emergent narratives.
Comparative Analysis Tool: Build a tool that tracks sentiment across multiple languages and compares the leading themes against mainstream topics. For instance, using the forming themes of "world" and "environment," you can analyze how different regions are framing regulatory discussions.
We invite you to explore these insights and applications further at pulsebit.lojenterprise.com/docs. You can copy-paste the code we shared and get this running in under 10 minutes. By leveraging these capabilities, you can ensure your models stay ahead of global sentiment trends.

English coverage led by 24.6 hours. Italian at T+24.6h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.

Top comments (0)