Your pipeline just missed a critical 24-hour momentum spike of +1.600 in environmental sentiment, highlighting a glaring oversight in managing multilingual sources. This anomaly reveals a significant gap in your data processing: the leading language was English, yet your pipeline lagged behind by 15.7 hours. While you were busy analyzing other themes, a cluster of stories around "France's Climate Agenda Excluded from G7 Talks" emerged, and that’s important for understanding the evolving narrative on climate policy. If you’re not capturing these spikes in real time, you’re missing out on critical sentiment shifts that can influence your strategy.

English coverage led by 15.7 hours. Da at T+15.7h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
If your pipeline doesn't accommodate multilingual origins or dominant entities, you're likely facing a structural gap. You might be thinking, "My model missed this by 15.7 hours," and that's a significant loss in actionable intelligence. The leading English press articles, clustered around themes of climate and environment, went unnoticed because of this delay. In today's fast-paced environment, any lag can lead to missed opportunities or misguided strategies.
To catch these trends, we can utilize our API to filter sentiment data effectively. Below is a concise Python snippet that captures this anomaly:
import requests
*Left: Python GET /news_semantic call for 'environment'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'environment'
momentum = +1.600
confidence = 0.85
lang = 'en'
# Geographic origin filter
response = requests.get(f"https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}&momentum={momentum}&confidence={confidence}")
data = response.json()
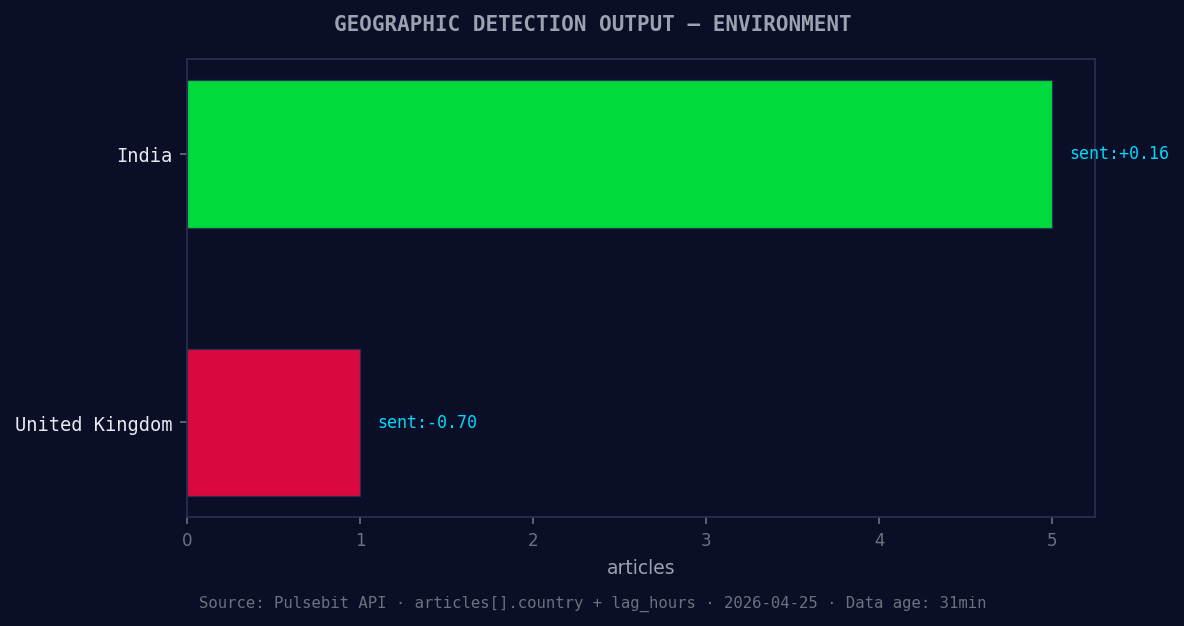
*Geographic detection output for environment. India leads with 5 articles and sentiment +0.16. Source: Pulsebit /news_recent geographic fields.*
# Meta-sentiment moment
narrative = "Clustered by shared themes: climate, environment, talks, france, drops."
sentiment_analysis = requests.post("https://api.pulsebit.com/sentiment", json={"text": narrative})
sentiment_data = sentiment_analysis.json()
print("Filtered Data:", data)
print("Sentiment Analysis:", sentiment_data)
In this code, we first filter for English-language articles related to the environment with a specified momentum and confidence. Next, we analyze the narrative string that explains our clustering, which provides additional insights into the sentiment framing. This two-step process ensures we're not only capturing data but also understanding the context and implications of that data.
Now, let’s explore three specific builds you can implement using this pattern:
Geo-Filtered Alerts: Set up an alert system that triggers when the environmental sentiment momentum surpasses a threshold of +1.500 for English articles. This ensures you’re immediately aware of significant shifts tied to geographical relevance.
Meta-Sentiment Dashboard: Create a dashboard that visualizes the meta-sentiment analysis of clustered narratives. For instance, feed the string "Clustered by shared themes: packaging, earth, day" into our API to fetch real-time sentiment scores and display them alongside trending topics.
Forming Themes Tracker: Build a tracker that monitors forming themes, such as environment(+0.00) and google(+0.00) versus mainstream tags like packaging and earth. Use a threshold of +0.500 for sentiment scores to identify emerging narratives that can influence your content strategy.
By integrating these builds into your pipeline, you can ensure you’re not only catching up but also staying ahead in the rapidly evolving landscape of environmental sentiment.
Ready to get started? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run the code above in under 10 minutes, putting you on the fast track to capturing key insights and driving your decision-making process forward.

Top comments (0)