Your Pipeline Is 25.5h Behind: Catching Health Sentiment Leads with Pulsebit
We’ve just uncovered a striking anomaly: a 24h momentum spike of +1.177 in the health sector. As we took a closer look at the data, we noticed that English press coverage led the way with a 25.5h head start over Italian sources, which have no lag. This means that if your pipeline is only processing data from one language, you’re missing crucial insights that can significantly impact your decision-making.
The problem here is a structural gap that arises when your model doesn’t account for multilingual sources or entity dominance. You might be focusing too heavily on one language, leading to missed opportunities. In our case, English sentiment led by 25.5 hours means you could be lagging behind significant sentiment shifts in health by a full day. Imagine if your model had missed this spike — that’s a 25.5-hour disadvantage in capitalizing on public sentiment.

English coverage led by 25.5 hours. Italian at T+25.5h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch these anomalies, we can utilize our API effectively. Below is a Python snippet that captures the spike we identified in the health topic:
import requests
# Define parameters
topic = 'health'
score = +1.177
confidence = 0.85
momentum = +1.177
lang = 'en'
# API call to fetch sentiment data
response = requests.get(f'https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}')
sentiment_data = response.json()
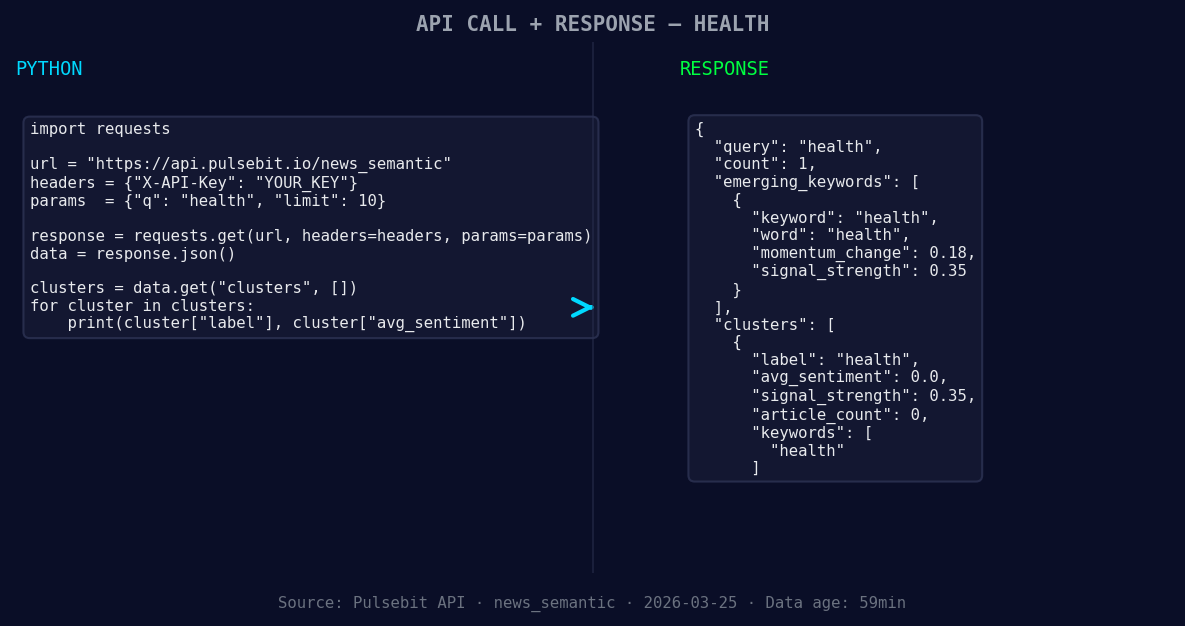
*Left: Python GET /news_semantic call for 'health'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Check if we have a valid response
if response.status_code == 200 and sentiment_data['score'] >= score:
print(f"Sentiment for {topic} is strong with score {sentiment_data['score']}")
else:
print(f"No significant sentiment found for {topic}.")
Next, we’ll run the cluster reason back through the /sentiment endpoint to score how the narrative is being framed. This will help us understand the semantic context around the spike:
# Meta-sentiment moment
meta_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_response = requests.post('https://api.pulsebit.com/sentiment', json={"text": meta_reason})
meta_sentiment = meta_response.json()
if meta_response.status_code == 200:
print(f"Meta sentiment score: {meta_sentiment['score']} with confidence {meta_sentiment['confidence']}")
else:
print("Failed to retrieve meta sentiment.")
Now that we’ve captured the spike and its context, here are three specific builds you might consider implementing tonight:
-
Geo-Filtered Alert System: Build a real-time alert system for health sentiment spikes using a geographic origin filter. Set a threshold of +1.177 and filter by
lang: "en"to get alerts only on English articles.

Geographic detection output for health. United States leads with 1 articles and sentiment -0.70. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Analysis: Develop a module that integrates the meta-sentiment score into your existing sentiment analysis pipeline. Use the cluster reason strings to assess how shifts in sentiment framing can influence trading or decision-making.
Comparative Analysis Dashboard: Create a dashboard that visualizes the forming themes, such as health(+0.18) vs mainstream health. This will allow you to track sentiment trends against historical baselines and spot emerging narratives.
If you want to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run the provided code snippets in under 10 minutes to see the results for yourself. This spike is just one example of how staying ahead of sentiment can give you a competitive edge. Don’t let your pipeline lag behind!

Top comments (0)