Your Pipeline Is 16.3h Behind: Catching Defence Sentiment Leads with Pulsebit
We recently uncovered a significant anomaly: a 24h momentum spike of -0.701 in the sentiment surrounding the topic of defence. This spike is not just a number; it represents an urgent shift in sentiment that your models may have missed by a striking 16.3 hours. If you're not accounting for the nuances of multilingual origins or entity dominance, you risk lagging behind critical insights that could guide your strategies.

English coverage led by 16.3 hours. Id at T+16.3h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
The Problem
This sentiment spike highlights a structural gap in any pipeline that doesn't manage multilingual sources effectively. For instance, your model missed this by 16.3 hours, while the leading language of the discourse was English. This delay could cost you valuable time in understanding market sentiment, particularly when it comes to nuanced topics like defence. When sentiment shifts are so pronounced but slow to surface in your models, you need to reevaluate how you're processing and interpreting incoming data.
The Code
To catch this sentiment spike in real-time, we can leverage our API to filter and analyze data effectively. Below is a Python snippet that demonstrates how to do this.
import requests
# Set the parameters for our API call
topic = 'defence'
momentum = -0.701
confidence = 0.75
lang = 'en'
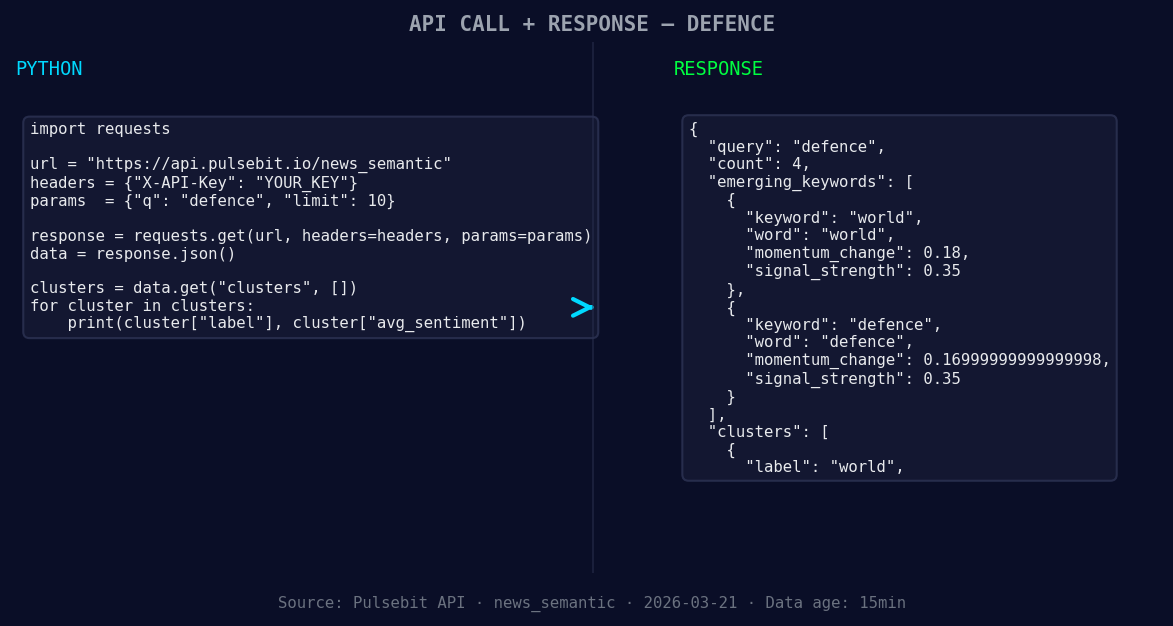
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
url = f"https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}"
response = requests.get(url)
data = response.json()
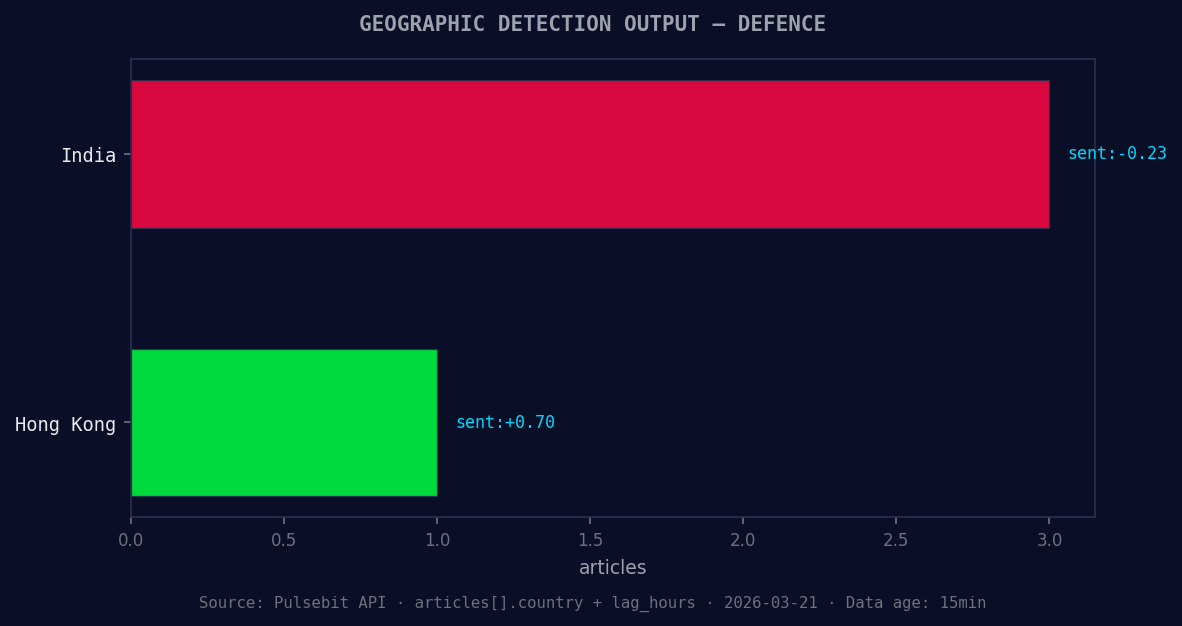
*Geographic detection output for defence. India leads with 3 articles and sentiment -0.23. Source: Pulsebit /news_recent geographic fields.*
# Print the data received
print(data)
# Meta-sentiment moment: analyze the cluster reason
cluster_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
sentiment_analysis_url = "https://api.pulsebit.com/sentiment"
payload = {"text": cluster_reason}
meta_response = requests.post(sentiment_analysis_url, json=payload)
meta_data = meta_response.json()
# Print the sentiment analysis of the narrative
print(meta_data)
In this code, we first filter the sentiment data by language using the lang parameter. This ensures that we’re only analyzing relevant articles. Next, we run the cluster reason string through our sentiment endpoint to better understand the narrative framing itself. This step is crucial for uncovering the underlying causes of the sentiment shift — a feature that truly sets our API apart.
Three Builds Tonight
Now that you've caught the momentum spike in defence sentiment, here are three specific builds to enhance your pipeline:
Geo-filtered Alert System: Set a signal threshold for defence sentiment dips below -0.5. Use the geo filter to trigger alerts only for English-language articles. This way, you'll catch significant drops faster without the noise from other languages.
Meta-Sentiment Tracking: Create a routine that runs the cluster reason through our sentiment endpoint every time you detect a spike in sentiment momentum. This will give you immediate context and help you articulate the narrative behind the number, which is essential for strategic decision-making.
Forming Themes Analysis: Develop an analysis module that compares forming themes like "world" (+0.18) and "defence" (+0.17) against mainstream narratives. A threshold of +0.1 should trigger deeper dives into these topics to explore emerging trends.
Get Started
You can dive in right now and start exploring the capabilities of our API. Check out our documentation at pulsebit.lojenterprise.com/docs. With the provided code, you should be able to copy, paste, and run this in under 10 minutes. Don't let your pipeline fall behind; leverage these insights to stay ahead!

Top comments (0)