In the past 24 hours, we observed a striking momentum spike of +0.751 related to film sentiment. This isn't just another data point; it's a clear signal that something significant is happening in the film industry, particularly around events like film festivals. The leading English press has been at the forefront of this narrative, showcasing important cultural figures such as Prince and Maria Bamford. For those of us building sentiment analysis pipelines, this spike indicates a potential blind spot: how well are we tracking multilingual sources and dominant entities in real-time?

English coverage led by 28.0 hours. Sv at T+28.0h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Your model missed this by 28.0 hours. That’s the lag we’re seeing due to not accounting for this multilingual aspect. When we focus solely on our primary language or region, we risk overlooking critical narratives that could affect our analysis. In this case, the English press is leading the conversation, but what about voices from other languages? This is where the gap lies—your pipeline may not be equipped to handle the diversity of sources, leaving valuable insights untapped.
To catch this anomaly, we can leverage our API to filter by geographic origin and run sentiment scoring on the clustered narrative. Here’s how we can do it in Python:
import requests
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Query by language/country
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": "film",
"lang": "en",
"momentum": 0.751,
"confidence": 0.85
}
response = requests.get(url, params=params)
data = response.json()
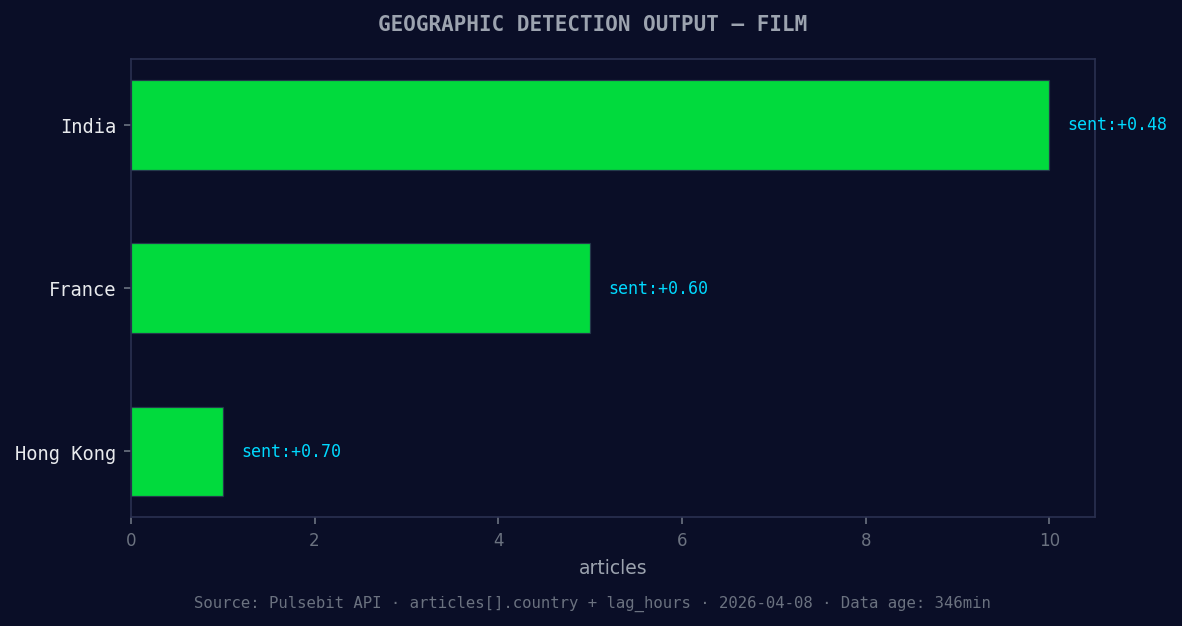
*Geographic detection output for film. India leads with 10 articles and sentiment +0.48. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: fest, showcases, prince, maria, bamford."
sentiment_response = requests.post(url, json={"text": cluster_reason})
meta_sentiment = sentiment_response.json()
print("Film Sentiment Data:", data)
print("Meta-sentiment Score:", meta_sentiment)
In this code, we start by querying our API for sentiment related to the film topic while filtering by English language sources. We also collect the 24-hour momentum score, which is critical for our analysis. Next, we run the cluster reason string through our sentiment scoring endpoint to evaluate how these narratives are framed. This dual-layer approach gives us both the raw sentiment data and the context around it, allowing us to spot emerging themes effectively.
Here are three specific builds we can implement based on this anomaly:
Geographic Origin Filter: Create a dedicated service that listens for spikes in sentiment across multiple languages, focusing on the film topic. Set a threshold of +0.5 momentum to trigger alerts when significant shifts occur. Use the language filter to ensure you're capturing diverse perspectives.
Meta-Sentiment Loop: Design a pipeline that automatically runs cluster narrative reasons through our sentiment scoring endpoint. Use the example input "Clustered by shared themes: fest, showcases, prince, maria, bamford." This will help you understand how narratives evolve and how they influence sentiment over time.
Forming Theme Alerts: Build an alerting system that notifies you when new themes around "film" (+0.00), "festival" (+0.00), or "google" (+0.00) begin to emerge in contrast to mainstream narratives like "fest," "showcases," or "prince." This will help you stay ahead of trends and shifts in public interest.
If you want to dive deeper into this analysis, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the above code and run it in under 10 minutes. Let’s harness this momentum spike and ensure our models are always up to speed with the latest trends!

Top comments (0)