Your Pipeline Is 28.3h Behind: Catching Finance Sentiment Leads with Pulsebit
We recently observed a remarkable anomaly: a 24h momentum spike of +0.427 in finance sentiment. The leading language driving this spike was English, with a notable 28.3-hour lead. This insight stems from our analysis of clustered stories, particularly one titled "Stock market today: Dow, S&P 500, Nasdaq rise on Iran deal hopes, cooler-than-ex," which was referenced in two separate articles. This spike in finance sentiment signifies that there is a developing narrative which could yield actionable insights.
However, if your sentiment analysis pipeline isn't designed to handle the nuances of multilingual origins or entity dominance, you might have missed this opportunity by a staggering 28.3 hours. The dominant entity in this narrative, English, suggests that stories in other languages may not have made it onto your radar. Your model could be operating with outdated or incomplete data, leaving you blind to critical trends that can inform your trading or investment strategies.

English coverage led by 28.3 hours. Id at T+28.3h. Confidence scores: English 0.95, French 0.95, Spanish 0.95 Source: Pulsebit /sentiment_by_lang.
To illustrate how we can leverage this insight, let’s delve into the code that extracts this valuable information from our API.
First, we can filter our queries to focus on the English-language sentiment for the finance topic. Here’s an example of how to make that API call:

Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
import requests
# Define the parameters for the API call
params = {
"topic": "finance",
"score": +0.458,
"confidence": 0.95,
"momentum": +0.427,
"lang": "en" # Geographic origin filter
}
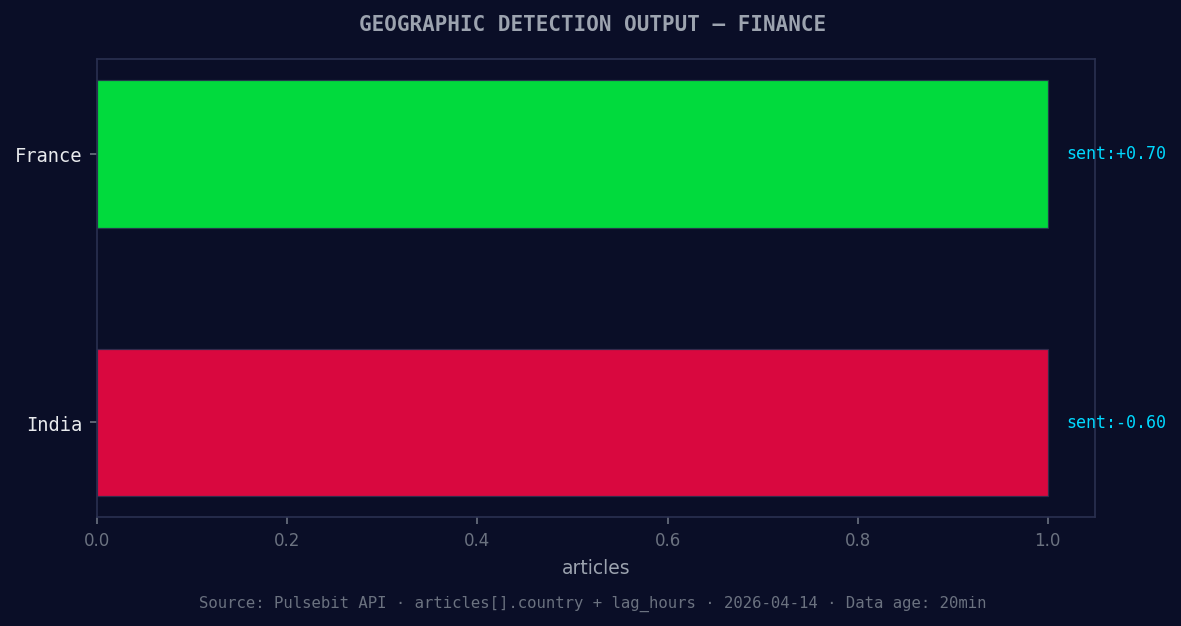
*Geographic detection output for finance. France leads with 1 articles and sentiment +0.70. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get('https://api.pulsebit.com/v1/sentiment', params=params)
data = response.json()
print(data)
Next, we need to run a meta-sentiment analysis on the clustered reason string to score the narrative framing itself. This is essential for understanding how the sentiment is contextualized. We’ll post the cluster's themes back through our sentiment endpoint:
# Define the cluster reason string
cluster_reason = "Clustered by shared themes: proposed, rule, reform, financial, institution."
# Make the API call to score the narrative framing
meta_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={"text": cluster_reason})
meta_data = meta_response.json()
print(meta_data)
With these two pieces of code, you can start capturing and analyzing sentiment spikes effectively.
Now that we’ve covered how to catch this emerging trend, let’s discuss three specific builds you could implement tonight:
Sentiment Alerts for Finance: Set an alert for any sentiment spikes greater than +0.4 in English. This threshold can trigger notifications for potential market-moving events.
Geo-Filtered News Aggregator: Build a service that aggregates finance-related articles only from English-speaking sources. This could utilize the geo filter to ensure you’re catching relevant narratives without noise from other languages.
Meta-Sentiment Analysis Dashboard: Create a dashboard that visualizes the meta-sentiment scores for clustered narratives, such as those regarding finance, Google, and S&P. By analyzing the framing around terms like "proposed," "rule," and "reform," you can better understand how these themes influence market sentiment.
If you’re eager to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code snippets and run them in under 10 minutes. This is your chance to refine your pipeline and enhance your sentiment analysis capabilities. Don’t let another 28.3 hours slip by!

Top comments (0)