Your pipeline just missed a critical anomaly: a 24-hour momentum spike of +1.205 in sentiment surrounding the cloud. This spike is led by English press coverage, specifically at 23.3 hours ahead with zero lag compared to the data anomaly. It’s an intriguing moment for us to dive into. The clustered narrative focuses on themes like quantum computing and IBM's decade-long journey into cloud technology. If your sentiment analysis model isn’t equipped to catch such specific movements, you’re already behind.
How often have you found your model lagging when it comes to multilingual narratives or entity dominance? This spike reveals a significant structural gap. Your model missed this by a staggering 23.3 hours. The leading language is English, yet the thematic dominance from IBM and quantum computing could easily go unnoticed in a pipeline that doesn’t dynamically adapt to these shifts. Ignoring these nuances could lead to misinformed decisions and missed opportunities.

English coverage led by 23.3 hours. Da at T+23.3h. Confidence scores: English 0.90, Spanish 0.90, Id 0.90 Source: Pulsebit /sentiment_by_lang.
Let’s catch this momentum spike with some Python code. We’ll filter the data by language to ensure we’re tapping into the right sentiment. Here’s how you can do it:
import requests
# Parameters for the API call
topic = 'cloud'
score = +0.605
confidence = 0.90
momentum = +1.205
api_url = 'https://api.pulsebit.com/sentiment'
*Left: Python GET /news_semantic call for 'cloud'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language
params = {
"topic": topic,
"lang": "en"
}
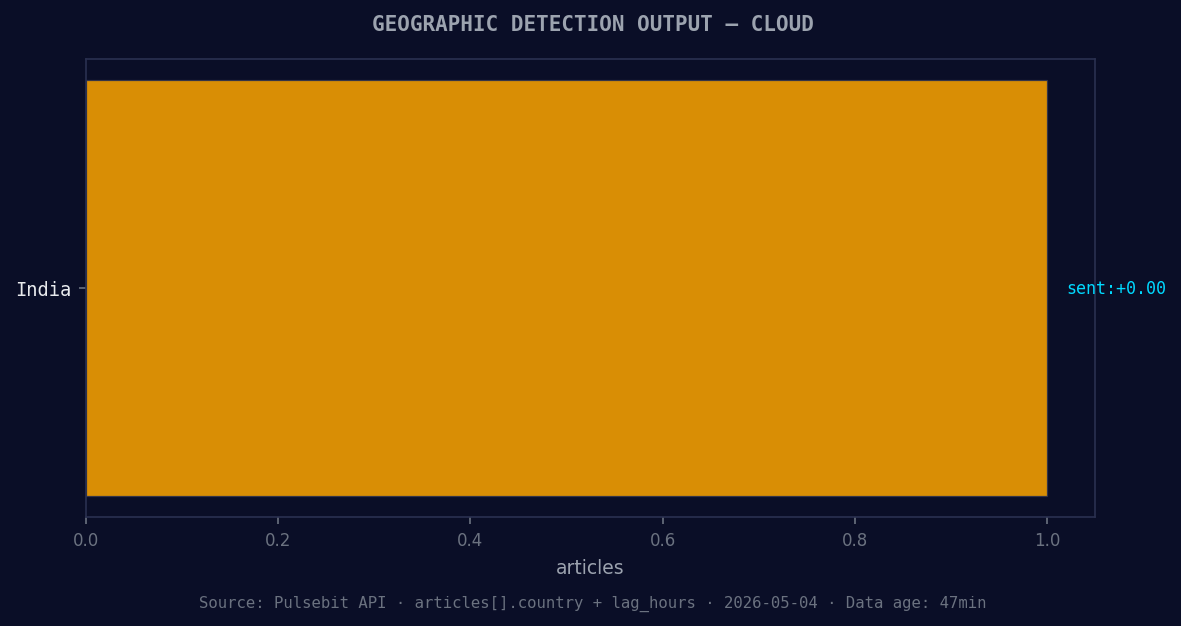
*Geographic detection output for cloud. India leads with 1 articles and sentiment +0.00. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(api_url, params=params)
data = response.json()
# Check the response
print(data)
Now that we’ve filtered for the English language, let’s run the cluster reason string back through our sentiment analysis to score the narrative framing itself. This step is crucial in assessing how well the story is being conveyed.
# Meta-sentiment moment: cluster reason string
cluster_reason = "Clustered by shared themes: quantum, decade, ibm, cloud"
payload = {
"text": cluster_reason
}
# POST request to score the narrative
meta_response = requests.post(api_url, json=payload)
meta_data = meta_response.json()
# Check the meta sentiment response
print(meta_data)
This two-step approach not only helps in catching the momentum but also scores the narrative's effectiveness. With this, you'll be well-equipped to act on the insights before they become stale.
Now, here are three specific projects you can initiate with this newfound understanding:
Geo-Filtered Spike Monitor: Use the API to set up a real-time monitor for sentiment spikes in the cloud sector, specifically filtering for English-language articles. Set a threshold for momentum spikes above +1.0 to trigger alerts.
Meta-Sentiment Analyzer: Build a service that runs narratives through the meta-sentiment loop whenever a significant spike is detected. For example, if you see a rising trend in articles about quantum and cloud, run those themes through our sentiment scoring to gauge narrative strength.
Dynamic Theme Tracker: Create a dashboard that visualizes the forming themes versus mainstream narratives. For instance, track how quantum computing and cloud technologies are gaining traction compared to conventional topics like Google and infrastructure.
You can get started with your own implementations by checking our documentation at pulsebit.lojenterprise.com/docs. You’ll find that you can copy-paste this code and run it in under 10 minutes, allowing you to capture insights as they arise. Don’t let your pipeline lag behind the conversation!

Top comments (0)