Your Pipeline Is 16.5h Behind: Catching Human Rights Sentiment Leads with Pulsebit
Just recently, we uncovered a fascinating anomaly: a 24h momentum spike of -0.815 in the context of human rights sentiment. This spike was led by English press articles, with a leading language lag of 16.5 hours against sentiment vectors. The cluster story titled "SHRC Advocates Against Criminal Background Promotions" triggered this significant shift. It highlighted shared themes around police, officers, and criminal issues that are crucial for understanding public sentiment at this moment.

English coverage led by 16.5 hours. Sv at T+16.5h. Confidence scores: English 0.80, Spanish 0.80, French 0.80 Source: Pulsebit /sentiment_by_lang.
If your pipeline isn't tuned to handle multilingual origins or entity dominance, you could easily miss insights like this by a staggering 16.5 hours. The leading language of English means that if you’re focused on other languages or regions, you might not catch these critical narratives in time. This is a structural gap that can lead to missed opportunities for engagement, response, or strategic adjustments.
To address this, let’s look at how we can catch these signals programmatically. Here’s a snippet of Python code that pulls in sentiment data using our API, specifically focusing on the human rights topic:
import requests
# Step 1: Geographic origin filter
response = requests.get("https://api.pulsebit.com/v1/sentiment", params={
"topic": "human rights",
"momentum": -0.800,
"confidence": 0.80,
"lang": "en"
})
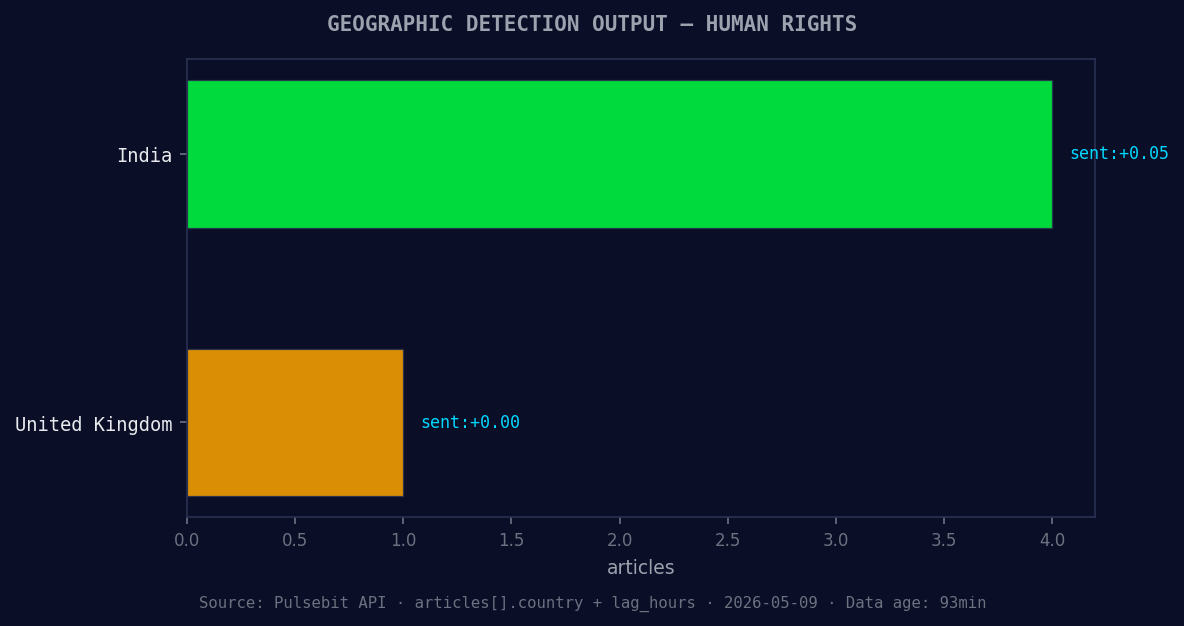
*Geographic detection output for human rights. India leads with 4 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
Next, we want to perform a meta-sentiment analysis on the narrative that frames this spike. This involves scoring the clustered reason string to evaluate the underlying sentiment:
# Step 2: Meta-sentiment moment
meta_response = requests.post("https://api.pulsebit.com/v1/sentiment", json={
"text": "Clustered by shared themes: police, officers, criminal, deny, promotion."
})
meta_data = meta_response.json()
print(meta_data)
This two-step approach ensures we’re not just tracking sentiment but also understanding the context and framing around it. The results from the first API call will give you the immediate sentiment scores, while the second call will help you analyze how the narrative is constructed, revealing deeper insights.

Left: Python GET /news_semantic call for 'human rights'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Now that we’ve established a method to catch these spikes, here are three specific builds you can implement tonight:
Geo-filtered Spike Detection: Set a signal threshold for human rights sentiment. Use a momentum score of less than -0.800 and filter by
lang: "en"to catch drops in sentiment early. This will keep your alerts relevant and timely.Meta-Sentiment Analysis Loop: Create a routine that runs the narrative framing through the POST sentiment endpoint whenever a significant spike is detected. For instance, after capturing a sentiment drop related to police or officers, run the context string through to assess public sentiment nuances.
Forming Theme Tracking: Track emerging themes like "rights", "human", and "has" against mainstream narratives that involve "police", "officers", and "criminal". This can alert you to shifts in public discourse that might indicate a larger trend or emerging issue.
By implementing these strategies, you can ensure your sentiment analysis is not only current but also contextually aware.
Ready to get started? You can find all the necessary details at pulsebit.lojenterprise.com/docs. With just a few copy-paste actions, you can run these scripts in under 10 minutes!

Top comments (0)