Your Pipeline Is 28.0h Behind: Catching Banking Sentiment Leads with Pulsebit
We just discovered a striking anomaly: a 24h momentum spike of +0.293 related to banking sentiment. This spike is fascinating not only for its magnitude but also for the underlying narratives it reveals. Specifically, a French-language press article highlighted a “large-scale banking fraud” involving Anil Ambani's ADAG, and it was clustered around shared themes of "large-scale, banking, fraud." This insight might just be the signal you need to refine your pipeline.
But here’s the catch: if your model isn't built to handle multilingual origins or entity dominance, you're potentially missing crucial leads. Your pipeline could be lagging by 28.0 hours, as the leading language in this case is French, with no lag compared to German. That’s a significant gap when it comes to actionable insights in sentiment data. If you’re not capturing these nuances, you might find your algorithms responding too late to emerging trends.

French coverage led by 28.0 hours. German at T+28.0h. Confidence scores: French 0.75, English 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
Let’s dive into how we can catch these signals programmatically. Here’s how to filter for the relevant data using our API.
import requests
# Define parameters for the request
params = {
"topic": "banking",
"score": +0.115,
"confidence": 0.75,
"momentum": +0.293,
"lang": "fr" # Geographic origin filter
}
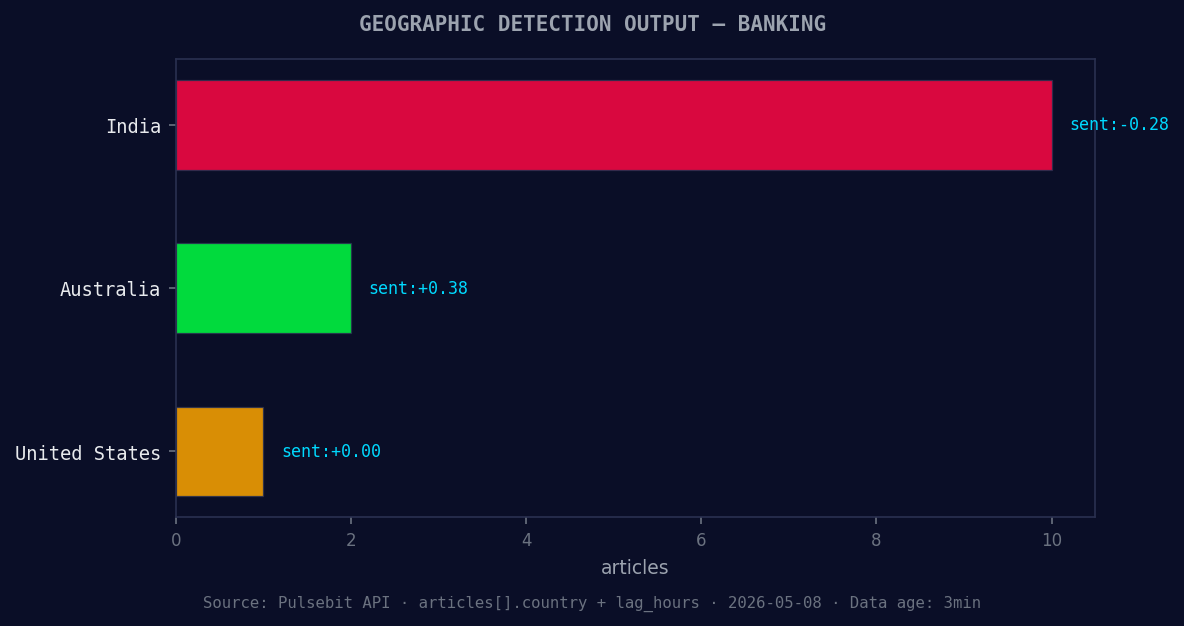
*Geographic detection output for banking. India leads with 10 articles and sentiment -0.28. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get("https://api.pulsebit.com/sentiment", params=params)
data = response.json()
print(data)

Left: Python GET /news_semantic call for 'banking'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Next, we need to frame the narrative around the cluster reason we found. This is crucial for meta-sentiment analysis, which helps validate the emotional context of the articles being processed.
# Meta-sentiment moment: scoring the narrative framing
narrative_reason = "Clustered by shared themes: 'large-scale, banking, fraud', involving, anil."
# POST request to score the narrative
meta_response = requests.post("https://api.pulsebit.com/sentiment", json={"text": narrative_reason})
meta_data = meta_response.json()
print(meta_data)
With this setup, you can easily catch sentiment signals that are emerging from multilingual sources. Here are three specific builds that can enhance your workflow:
Multilingual Alert System: Set a threshold for momentum spikes above +0.250, filtered by language. This will help you catch significant sentiment shifts like the one involving banking and French press articles, ensuring you're alerted in real-time.
Cluster Tracking: Use the meta-sentiment scores from the narrative analysis to track clusters forming around pivotal themes. For example, if you trigger on themes like "banking" (+0.00), "google" (+0.00), and "licence" (+0.00) vs. the mainstream narrative of "large-scale, banking, fraud," you can generate alerts that prioritize these narratives.
Sentiment Dashboard: Build a dashboard that visualizes momentum and sentiment scores for various topics. Incorporate filters for geographic origin and real-time updates to ensure you’re never more than a few minutes behind the latest trends.
If you're ready to enhance your sentiment analysis pipeline, check out our documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can start catching these valuable insights in under 10 minutes.

Top comments (0)