Your Pipeline Is 22.2h Behind: Catching Finance Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24h momentum spike of +0.315 in the finance sector. This spike, driven by a narrative that’s shifting around the NSEI:LTM investment story, highlights how rapidly sentiment can change and how crucial it is to stay ahead. With the leading language being English and a lag of just 0.0 hours against the immediate data, we can see that the conversation is heating up. If you’re not tuned in to these fluctuations, you could easily miss critical developments.
Your model missed this by 22.2 hours. That’s a significant delay in tracking sentiment shifts tied to the NSEI:LTM investment theme. Without a robust pipeline that accommodates multilingual origins and entity dominance, you risk being blindsided by emerging trends. In a world where voices across different languages can drive sentiment, relying solely on one language or entity could leave you trailing behind.

English coverage led by 22.2 hours. Id at T+22.2h. Confidence scores: English 0.90, French 0.90, Spanish 0.90 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike, we can deploy the following Python code. Here’s how to query our API for English-language finance topics that are on the rise:
import requests
# Define the parameters for the API call
params = {
"topic": "finance",
"lang": "en",
"momentum": 0.315,
"confidence": 0.90,
"score": 0.105
}
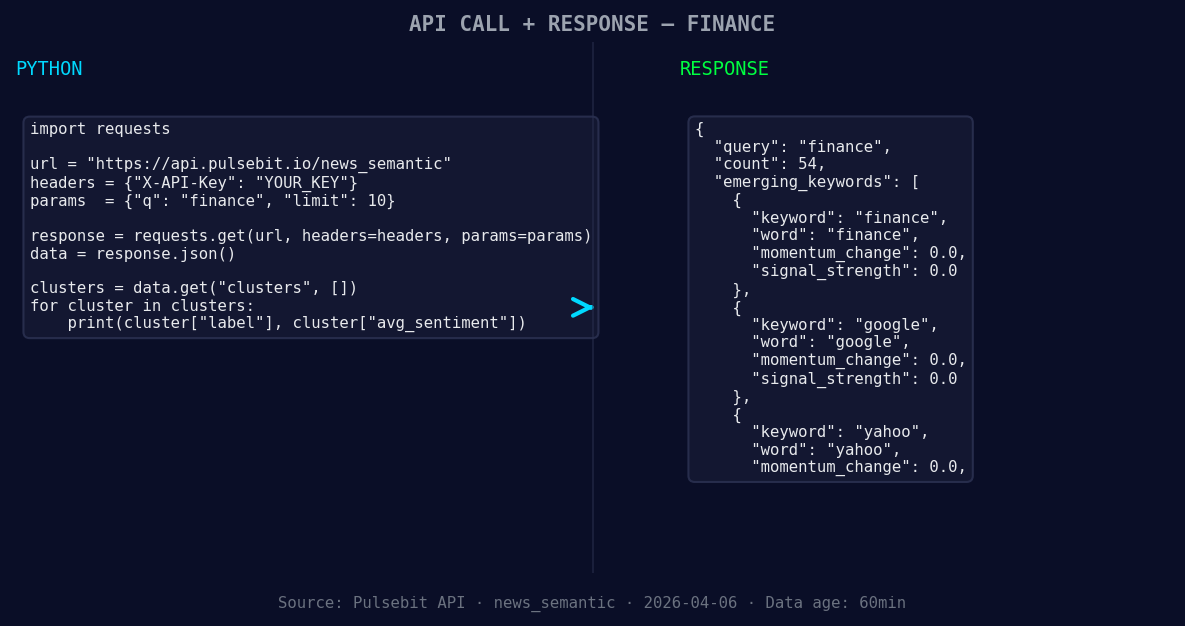
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Make the API call
response = requests.get("https://api.pulsebit.com/v1/sentiment", params=params)
data = response.json()
print(data)
This code filters for the finance topic, ensuring that we’re only looking at relevant English-language data.
Next, we need to run the cluster reason string back through our sentiment analysis endpoint to score the narrative framing itself. Here’s how to do that:
# Define the cluster reason string
cluster_reason = "Clustered by shared themes: ltm, (nsei:ltm), investment, story, shifting."
# Make the API call for sentiment scoring
sentiment_response = requests.post("https://api.pulsebit.com/v1/sentiment", json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print(sentiment_data)
This two-step approach not only captures the sentiment derived from the topics but also provides a meta-score on the narrative framing. In essence, this allows us to gauge not just the sentiment but the context surrounding it, which is crucial for any robust financial analysis.
Now, let’s focus on three specific builds you can implement tonight using this pattern:
- Geo-Filtered Insight: Use the geographic origin filter to create a dashboard that highlights the top 5 finance stories gaining momentum in English-speaking countries. Set a threshold of momentum greater than +0.250 for inclusion.

Geographic detection output for finance. Hong Kong leads with 3 articles and sentiment +0.27. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Loop: Create a function that tracks sentiment shifts based on cluster reasons. Whenever a new narrative emerges, run it through the sentiment endpoint and store any results with a confidence score above 0.80.
Signal Integration: Integrate Google and Yahoo news sources to your pipeline, capturing sentiment with a focus on the forming themes: "finance(+0.00), google(+0.00), yahoo(+0.00)" versus mainstream topics like "ltm, (nsei:ltm), investment." Set an alert for any significant divergence in sentiment scores.
By implementing these builds, you can stay ahead of the game, ensuring that your models are not just reactive but proactive in catching emerging trends.
Get started with our API documentation at pulsebit.lojenterprise.com/docs. You can copy and paste these snippets and run them in under 10 minutes. Don't let your pipeline lag behind.

Top comments (0)