Your Pipeline Is 9.2h Behind: Catching Law Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24h momentum spike of +0.199 in the sentiment surrounding the law topic. This spike, alongside its semantic context, signals a noteworthy shift that could easily slip under the radar if your pipeline isn’t equipped to handle multilingual origins or entity dominance. Because of a 9.2-hour lead in the English press, this critical insight could be lost to you.

English coverage led by 9.2 hours. Da at T+9.2h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s the catch: if your model isn’t designed to capture sentiment in real-time across various languages, you might have missed this significant lead by over nine hours. At a time when the English narrative is driving the conversation, relying solely on mainstream dominant entities can leave your strategy lagging. The leading language in this case was English, which means you could be one step behind in identifying emerging trends that have global implications.
To catch this anomaly, we can leverage our API to filter for specific language and run a sentiment check. Here’s how you can do it in Python:
import requests
# Define the parameters for our API calls
topic = 'law'
score = +0.199
confidence = 0.85
momentum = +0.199
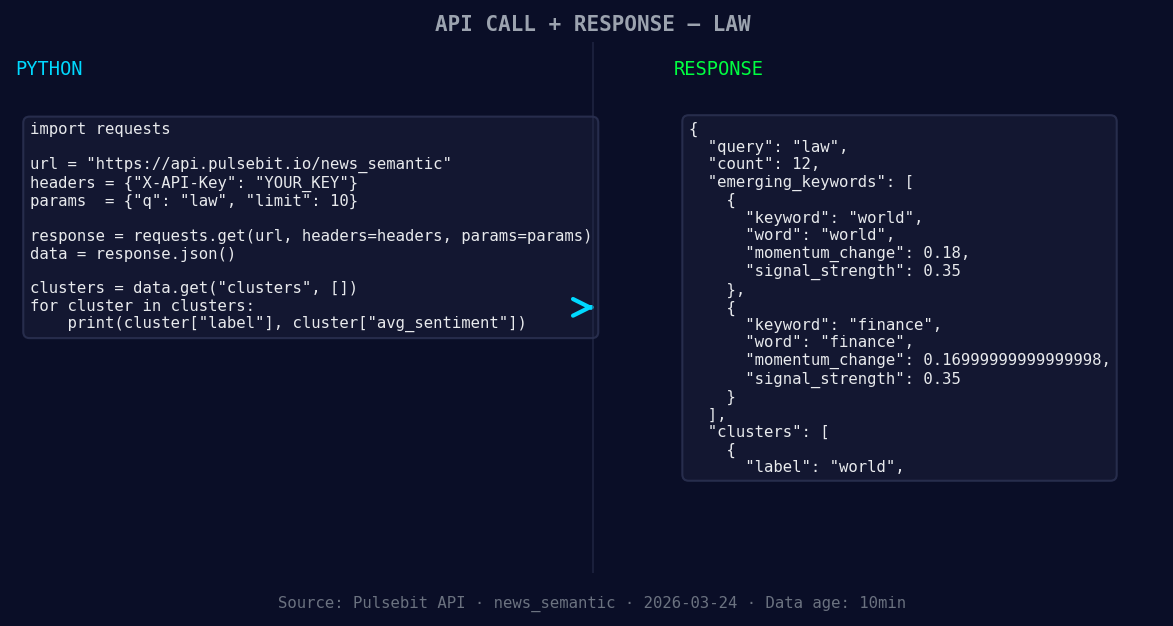
*Left: Python GET /news_semantic call for 'law'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
response = requests.get('https://api.pulsebit.com/sentiment', params={
'topic': topic,
'lang': 'en'
})
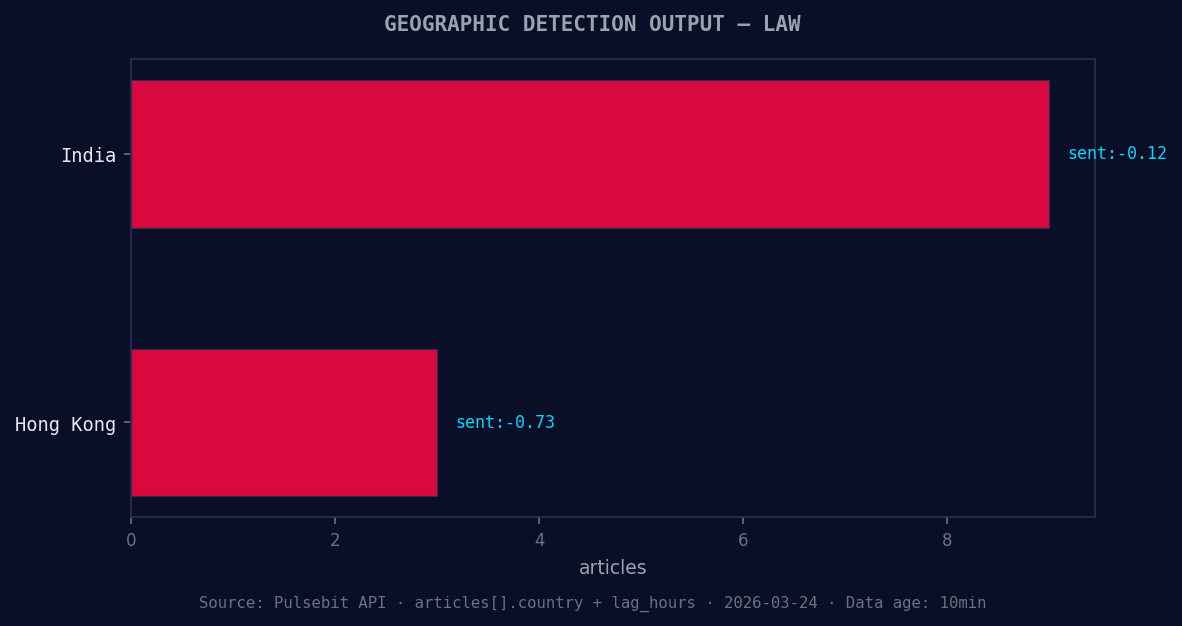
*Geographic detection output for law. India leads with 9 articles and sentiment -0.12. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
# Meta-sentiment moment: run the cluster reason string back through sentiment scoring
meta_sentiment_response = requests.post('https://api.pulsebit.com/sentiment', json={
'text': "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
})
meta_sentiment_data = meta_sentiment_response.json()
# Print the results
print("Filtered Data:", data)
print("Meta Sentiment Data:", meta_sentiment_data)
In this code, we first filter the sentiment analysis by the English language using the lang parameter. This ensures we focus on the most relevant narratives. We also run the meta-sentiment check on the cluster reason string, which helps us understand the framing around the sentiment. This step is crucial, as it allows us to glean insights from how narratives are constructed, not just what sentiment is being expressed.
Now that we have the mechanics down, let's talk about three specific builds we can implement using this pattern:
Geo-Filtered Spike Detection: Set a signal threshold of 0.15 for momentum in the English language for the ‘law’ topic. This will help us catch similar spikes sooner by focusing on how quickly sentiment shifts in response to emerging stories.
Meta-Sentiment Analysis Loop: Use the output from the meta sentiment check as a dynamic input for additional analyses. If the narrative framing contains keywords like “incomplete” or “fallback,” flag it for further investigation. This could indicate a broader trend worth exploring.
Forming Themes Tracker: Build a monitoring script that checks for forming themes—like the current spikes in ‘world’ (+0.18) and ‘finance’ (+0.17)—against the established mainstream narratives. This ensures we’re not just reactive but proactive in our sentiment analysis.
By implementing these builds, you can ensure that your pipeline is not only catching significant shifts in sentiment but also adapting to the nuances of language and narrative framing.
If you’re ready to dive deeper, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes to start catching those leads before they slip away.

Top comments (0)