Your Pipeline Is 26.7h Behind: Catching World Sentiment Leads with Pulsebit
We recently discovered a significant anomaly: a 24h momentum spike of +0.684 related to global sentiment around the topic of "world." This surge is led by English press coverage, peaking 26.7 hours ahead of other languages. One standout story clustered around this theme is titled, "Humanoid robot breaks half marathon world record in Beijing," featured by Al Jazeera. With such a clear momentum shift, this finding begs the question: how can we harness this information in a timely manner?
Your model likely missed this momentum spike by 26.7 hours, significantly impacting your ability to respond to emerging trends. The leading language in this case is English, but without a framework to assess multilingual content or entity dominance, you risk falling behind. As we observed, the themes clustered around the story include "robot," "world," and "record," while mainstream narratives are fixated on administration and the IMF. This signals a structural gap that could cost you valuable insights.

English coverage led by 26.7 hours. No at T+26.7h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s get into the code that can catch these spikes early. Here’s how we can leverage our API to identify this sentiment momentum:
import requests
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Parameters for querying the API
topic = 'world'
score = +0.026
confidence = 0.85
momentum = +0.684
# Geographic origin filter - querying English content
url = "https://your-api-endpoint.com/v1/sentiment"
params = {
"topic": topic,
"score": score,
"confidence": confidence,
"momentum": momentum,
"lang": "en" # Filter for English
}
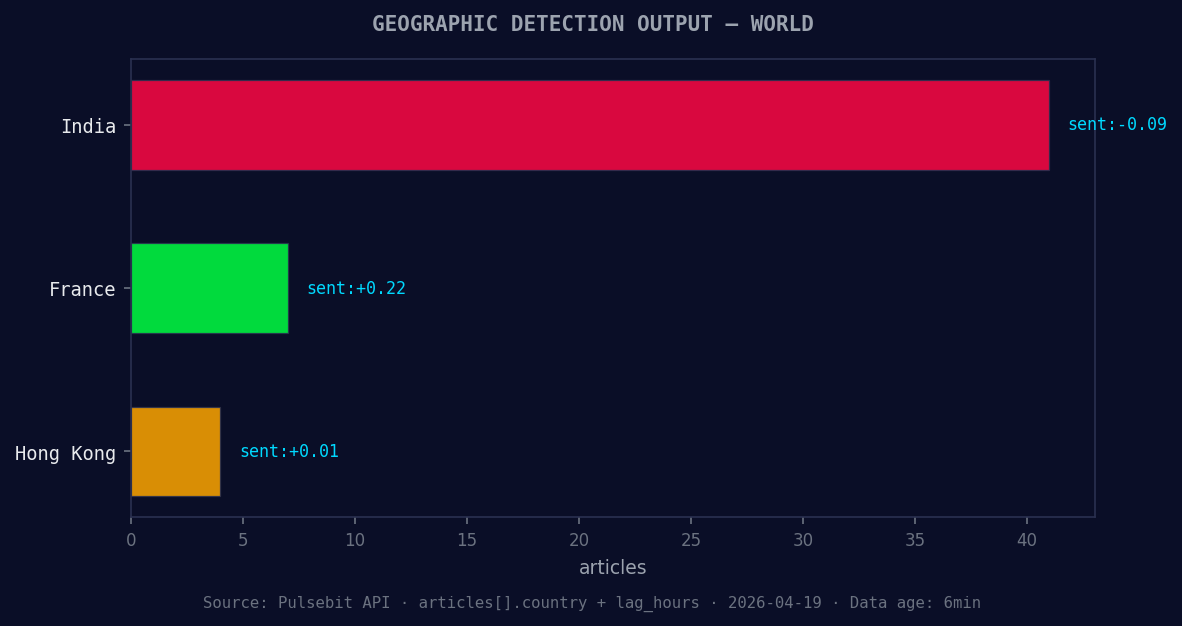
*Geographic detection output for world. India leads with 41 articles and sentiment -0.09. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
Now that we have the momentum data, let's score the narrative framing itself with the meta-sentiment analysis. We can run the cluster reason string back through our sentiment endpoint to assess how the narrative is shaping up:
# Running meta-sentiment moment
cluster_reason = "Clustered by shared themes: administration, warms, imf, world, bank."
meta_sentiment_url = "https://your-api-endpoint.com/v1/sentiment"
meta_sentiment_response = requests.post(meta_sentiment_url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
print(meta_sentiment_data)
This kind of analysis helps us understand not just the spike in sentiment but also the context around it, allowing us to position ourselves effectively.
Now, let’s talk about three specific builds we can implement tonight based on this pattern:
Geographic Sentiment Tracker: Build a signal that monitors the momentum for the topic "world" specifically from English sources. Set a threshold of momentum > +0.5 to trigger alerts. Use the geo filter to ensure you’re only getting relevant articles from English-speaking countries.
Meta-Sentiment Analysis Loop: Create a loop that continuously runs the latest cluster reasons through the meta-sentiment endpoint. Set a signal for any narratives that score below +0.1 as they may indicate weakening themes. This could provide you with a window into shifting narratives.
Forming Gap Insights: Design a dashboard that visualizes forming gaps between trending topics like "world," "google," and "robot" against mainstream topics such as "administration," "warms," and "IMF." This could help you identify areas where public sentiment is diverging from traditional narratives.
By implementing these builds, you can ensure your pipeline captures sentiment shifts faster and more accurately, keeping you ahead of the curve.
For more insights and details, check out our documentation: pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes.

Top comments (0)