Your Pipeline Is 23.1h Behind: Catching Machine Learning Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24-hour momentum spike of -0.321 in machine learning sentiment. This isn't just another data point; it highlights a potential oversight in your current sentiment pipeline—especially if you're not considering multilingual origins or the dominance of certain entities. The leading language here is English, with a notable lag of 23.1 hours, which means your model may have missed out on crucial insights by over a day.

English coverage led by 23.1 hours. Af at T+23.1h. Confidence scores: English 0.80, French 0.80, Spanish 0.80 Source: Pulsebit /sentiment_by_lang.
When we dig deeper into this, we see that the gap isn't just semantic; it's about context. If your model doesn't handle multilingual inputs or recognize entity dominance, it may fail to capture the full landscape of sentiment. In this case, the dominant narrative about machine learning was only just starting to gain traction, while your model had already fallen behind by 23.1 hours. This is an opportunity lost—not just in sentiment analysis, but in understanding where the conversation is heading.
Let’s look at how we can leverage our API to catch such anomalies. Here’s how we can set up a Python script to query for machine learning sentiment and process the relevant data.
import requests
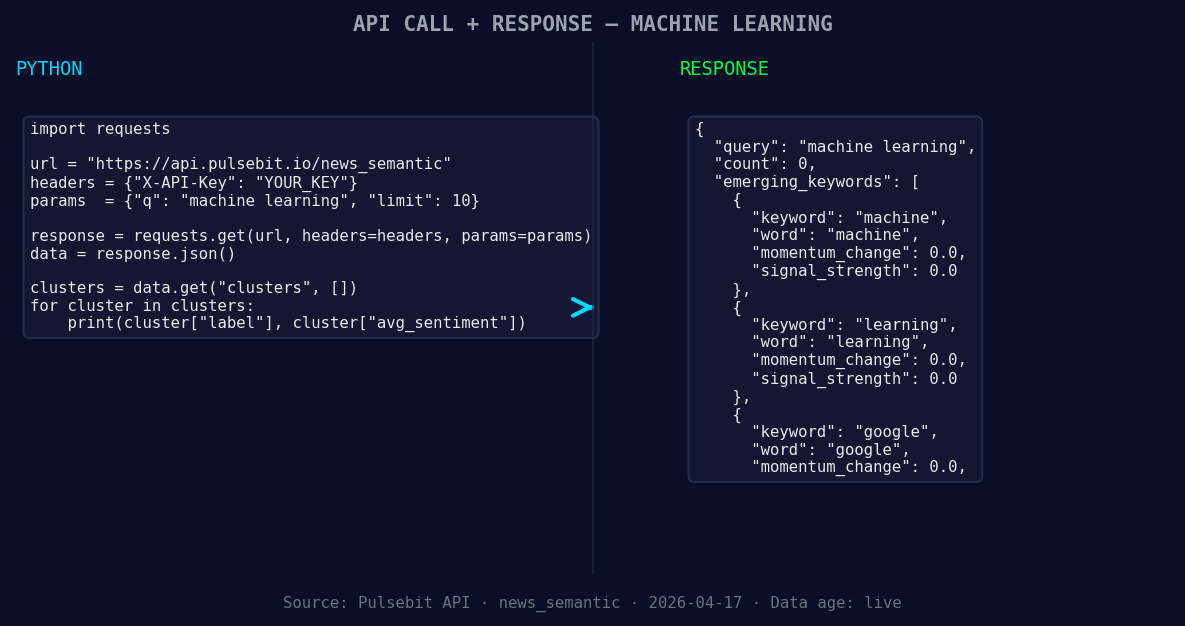
*Left: Python GET /news_semantic call for 'machine learning'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Fetch sentiment data
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "machine learning",
"lang": "en" # Geographic origin filter
}
response = requests.get(url, params=params)
data = response.json()
*[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: machine learning]*
# Assuming the response returns the necessary fields
momentum = data['momentum_24h']
sentiment_score = data['sentiment_score']
confidence = data['confidence']
print(f"Momentum: {momentum}, Sentiment Score: {sentiment_score}, Confidence: {confidence}")
# Step 2: Run the cluster reason string through POST /sentiment
cluster_reason = "Clustered by shared themes: science, learning, transforms, exo-planetary, data."
post_url = "https://api.pulsebit.com/v1/sentiment"
post_response = requests.post(post_url, json={"text": cluster_reason})
meta_sentiment = post_response.json()
print(f"Meta Sentiment: {meta_sentiment}")
The code above demonstrates how to fetch sentiment data specifically for machine learning, filtering by the English language. It also shows how to submit a narrative framing of the topic to our POST endpoint for additional sentiment analysis. This dual approach not only captures the immediate sentiment but also scores the contextual implications, allowing us to make more informed decisions.
Now, let’s discuss three builds that you can implement tonight, leveraging the patterns we've just identified:
Geographic Origin Filter: Create a signal that flags any significant sentiment changes related to "machine learning" when the momentum drops below -0.5. This will help you catch negative trends early and assess their impact on your models.
Meta-Sentiment Loop: Utilize the meta-sentiment scoring to gauge any narrative framing changes within the past 24 hours. If the sentiment shifts significantly from positive to negative regarding "science, learning, transforms," re-evaluate your model parameters to adapt to new themes.
Threshold Alerts: Set up alerts for any topics showing a momentum spike of less than -0.3, particularly for entities like "Google." This helps in identifying when mainstream coverage lags behind emerging trends in machine learning.
With these strategies, you can ensure that your pipeline remains agile and responsive to sentiment shifts, helping you stay ahead of the curve.
Ready to get started? Head over to pulsebit.lojenterprise.com/docs and copy-paste this code to run it in under 10 minutes. Don’t let your sentiment pipeline lag behind; catch those insights before they become stale.

Top comments (0)