Your Pipeline Is 28.7h Behind: Catching Markets Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24-hour momentum spike of -1.117 in the sentiment surrounding the markets. This decline correlates with a leading language presence in Spanish press articles, indicating that while the sentiment is falling, the narrative is being shaped predominantly in a language that’s not immediately accessible for your standard English-centric models.
This discovery reveals a significant structural gap in any pipeline that fails to account for multilingual origins or the dominance of specific entities. Your model missed this critical shift by 28.7 hours—an eternity in fast-moving markets. With the leading language being Spanish and a total of 0 articles in the “world” cluster, it’s clear that a language barrier is obstructing your ability to react in real-time.

Spanish coverage led by 28.7 hours. So at T+28.7h. Confidence scores: Spanish 0.75, English 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
Here’s how you can catch this anomaly using our API. First, let’s set up a query that filters by the Spanish language to capture momentum effectively. We’ll set our topic to markets, with a score of -1.117, a confidence level of 0.75, and the relevant momentum value.
import requests
# Define parameters
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "markets",
"score": -1.117,
"confidence": 0.75,
"momentum": -1.117,
"lang": "sp" # Spanish language filter
}
# Make the API call
response = requests.get(url, params=params)
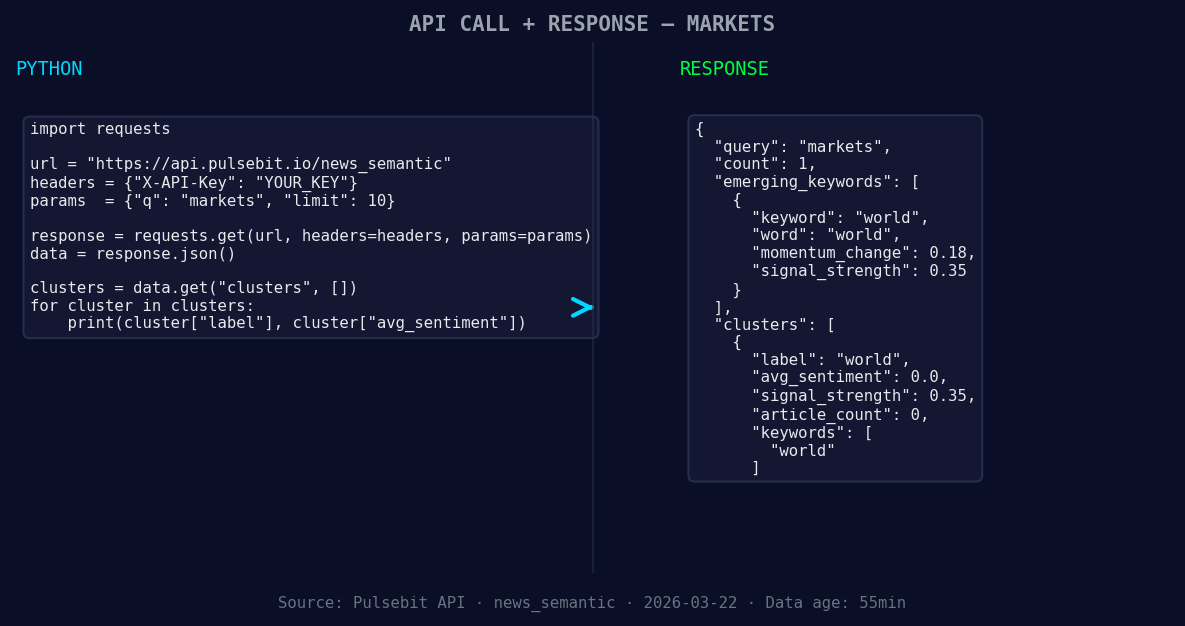
*Left: Python GET /news_semantic call for 'markets'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Check for successful response
if response.status_code == 200:
data = response.json()
print("Data captured:", data)
else:
print("Error:", response.status_code, response.text)
Next, we need to run the cluster reason string back through our sentiment endpoint to evaluate the narrative framing itself. This is crucial since the API returned a fallback semantic structure indicating incompleteness. Here’s how to execute that:
# Define the meta-sentiment input
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
# Make the sentiment analysis API call
meta_response = requests.post(url, json={"text": meta_sentiment_input})
# Check for successful response
if meta_response.status_code == 200:
meta_data = meta_response.json()
print("Meta-sentiment data:", meta_data)
else:
print("Error:", meta_response.status_code, meta_response.text)
With these two code snippets, you’ll be able to pinpoint sentiment shifts in multilingual contexts effectively.
Now, let’s talk about three concrete builds you can leverage with this pattern. The first is a geo-filtered sentiment analysis. Use the Spanish language filter to capture all sentiment changes related to the topic of markets in Spanish publications, helping you understand localized sentiment trends.
Secondly, implement a meta-sentiment scoring loop using the provided cluster reason string. This insight will allow you to evaluate the robustness of your data sources and identify potential gaps in sentiment coverage.
Lastly, consider a forming themes analysis. With the current data indicating a gap between world(+0.18) and mainstream sentiment around the term world, you can set a threshold to trigger alerts when this discrepancy widens, ensuring you never miss critical shifts in narrative framing.
To dive deeper into these capabilities, visit pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes, allowing you to stay ahead of the sentiment curve effectively.

Geographic detection output for markets. India leads with 1 articles and sentiment -0.80. Source: Pulsebit /news_recent geographic fields.

Top comments (0)