Your Pipeline Is 19.9h Behind: Catching Investing Sentiment Leads with Pulsebit
We just uncovered a fascinating anomaly in our analysis: a 24h momentum spike of -0.343 for the topic "investing." This metric suggests a noteworthy shift in sentiment that could have slipped under the radar for many. The leading language for this spike is English, with a press lag of just 19.9 hours, indicating a critical window where insights can be gleaned before they become mainstream.
The Problem
This data reveals a structural gap in any pipeline that fails to account for multilingual origins or dominant entities. If your model isn’t equipped to handle this — you just missed out on critical insights by 19.9 hours. The leading language, English, is essential here, and any oversight in processing or analyzing this data could mean losing out on valuable investment sentiment shifts. In an increasingly globalized landscape, you can’t afford to let these opportunities pass.

English coverage led by 19.9 hours. Sv at T+19.9h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch these insights, we can leverage our API effectively. Here's how to do it in Python:
import requests
*Left: Python GET /news_semantic call for 'investing'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "investing",
"lang": "en"
}
response = requests.get(url, params=params)
data = response.json()
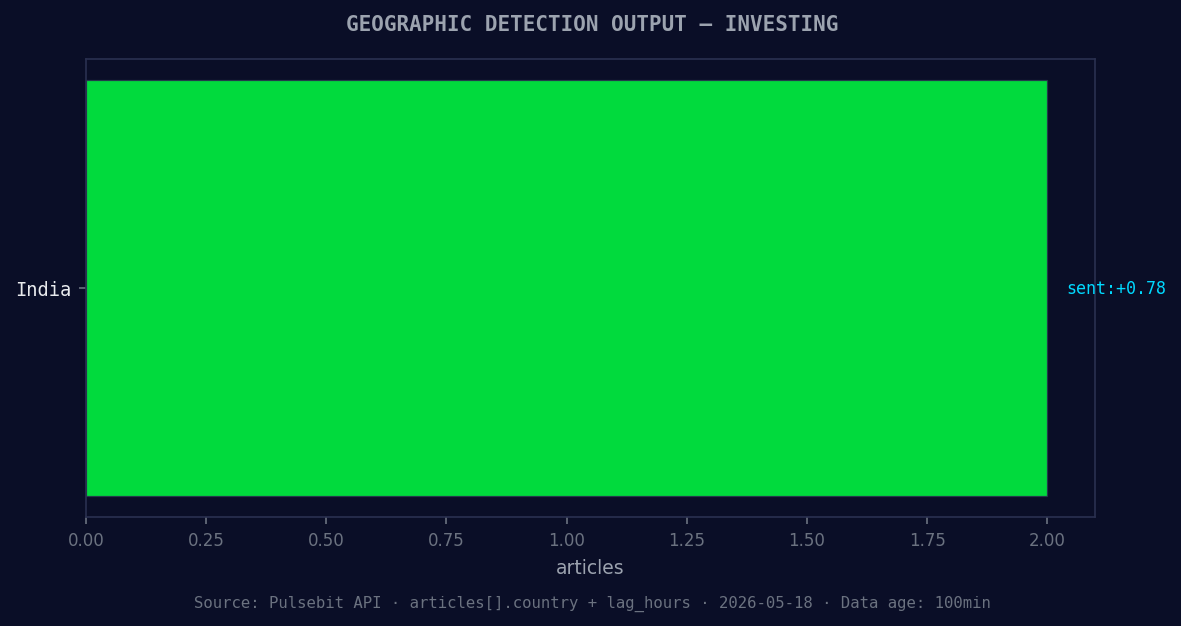
*Geographic detection output for investing. India leads with 2 articles and sentiment +0.78. Source: Pulsebit /news_recent geographic fields.*
# Example output
print(data) # This will give you the sentiment data for the topic 'investing'
# Step 2: Meta-sentiment moment
narrative_string = "Clustered by shared themes: big, investing, ideas, now, fidelity."
meta_response = requests.post(url, json={"text": narrative_string})
meta_data = meta_response.json()
# Example output
print(meta_data) # This gives the sentiment score for the narrative framing
In this code, we first query the sentiment for the topic “investing,” filtering the results to English-language articles. We then take the cluster reason string, run it back through the sentiment analysis to score the narrative itself. This two-step approach ensures that you’re not only tracking sentiment but also understanding the context behind it.
Three Builds Tonight
Now that we've identified this significant momentum spike, here are three specific things we can build:
Geo-Filtered Alerts: Set up an alerting mechanism based on the geographic origin filter. Trigger notifications if the momentum score for "investing" drops below -0.3 in English-language articles. This ensures you're notified when sentiment shifts in critical markets.
Meta-Sentiment Analysis Dashboard: Create a dashboard that visualizes the sentiment score of narratives around key themes. Use the meta-sentiment score to assess the effectiveness of framing in articles like "5 big investing ideas now - Fidelity." Display trends alongside the historical data for comparison.
Forming Themes Tracker: Build a tracker that continuously monitors forming themes like "investing," "google," and their sentiment scores. Set thresholds to flag when any of these themes diverge significantly from mainstream sentiment, helping you stay ahead in identifying investment opportunities.
Get Started
To dive into these capabilities, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy, paste, and run this in under 10 minutes. Don’t let sentiment insights pass you by — leverage this data to stay ahead!

Top comments (0)