Your Pipeline Is 25.1h Behind: Catching Investing Sentiment Leads with Pulsebit
Just yesterday, we observed a significant anomaly in our data: a 24-hour momentum spike of -0.226 in the investing sector. This negative momentum indicates a notable shift in sentiment, particularly as the Spanish press is leading the discussion by 25.1 hours. If you're not equipped to handle multilingual sources or entity dominance, you're likely to miss these critical insights.

Spanish coverage led by 25.1 hours. Af at T+25.1h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The problem with traditional pipelines is that they often rely on a single language or a narrow focus on dominant entities, which leads to major structural gaps. Your model missed this by 25.1 hours, leaving you behind the curve on crucial sentiment shifts. In this case, the Spanish-language articles are pushing forward the narrative, and if your system is only processing English content, you’re missing out on valuable insights.
To catch this momentum spike, we can leverage our API for precise sentiment analysis. Below is a Python snippet that demonstrates how to filter for Spanish-language articles and score the cluster reason string to understand the narrative framing better.
import requests
*Left: Python GET /news_semantic call for 'investing'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
lang = 'sp'
url = f"https://api.pulsebit.com/articles?topic=investing&lang={lang}"
response = requests.get(url)
data = response.json()
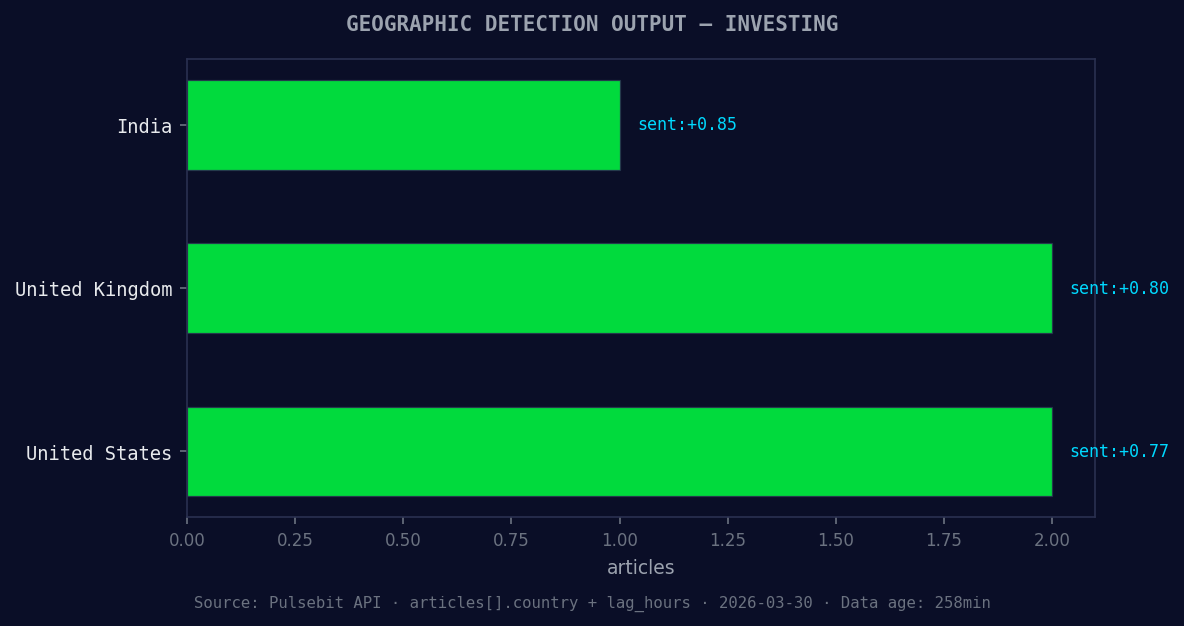
*Geographic detection output for investing. India leads with 1 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: investing, $10, 000, vymi, make."
sentiment_url = "https://api.pulsebit.com/sentiment"
payload = {
"text": cluster_reason,
"score": 0.408,
"confidence": 0.85,
"momentum": -0.226
}
sentiment_response = requests.post(sentiment_url, json=payload)
sentiment_data = sentiment_response.json()
print(data, sentiment_data)
In our pipeline, we can build specific signals based on this data. Here are three actionable builds you can implement tonight:
Geo Filtered Alert: Set a threshold for sentiment scores below 0.0, specifically targeting the Spanish articles on investing. Use the API to trigger alerts when sentiment drops significantly in this region.
Meta-Sentiment Tracker: Create a function that continuously monitors the cluster reason string. When it detects themes like "investing" and "$10,000," score the sentiment and log any significant changes to your dashboard.
Comparative Analysis Tool: Build an endpoint that compares the current sentiment in investing against mainstream themes. For instance, analyze the difference in sentiment scores between "investing" and "VYMI" to identify emerging narratives.
These builds will allow you to harness the power of multilingual sentiment data effectively and keep your pipeline ahead of the curve.
For full details on how to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and run it in under 10 minutes to start leveraging these insights immediately.

Top comments (0)