Your pipeline just missed a significant anomaly: the 24h momentum spike of -0.850 in food sentiment. This drop suggests an urgent need to reassess how we capture multi-lingual sentiment. The leading language for this anomaly was English, reflecting a sentiment lag of 22.6 hours behind the actual events. It’s time to hone in on these data points to ensure we’re not left in the dust while critical narratives unfold.
This revelation highlights a structural gap in any pipeline that doesn’t adequately handle multilingual origins or dominant entity themes. If your model isn’t equipped to process and prioritize diverse language inputs, it could easily miss vital shifts in sentiment. In this case, your model missed the food sentiment spike by 22.6 hours, while the dominant entity was the Hyderabad police, associated with a significant story about the seizure of adulterated food products. This gap could lead to missed opportunities or misguided strategies.

English coverage led by 22.6 hours. Af at T+22.6h. Confidence scores: English 0.85, French 0.85, No 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly in our pipeline, we can leverage our API. Here’s how you can do it in Python:
import requests
# Set up parameters for the API call
topic = 'food'
score = +0.430
confidence = 0.85
momentum = -0.850
*Left: Python GET /news_semantic call for 'food'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
url = 'https://api.pulsebit.com/v1/news'
params = {
'topic': topic,
'lang': 'en',
'threshold': score,
'confidence': confidence
}
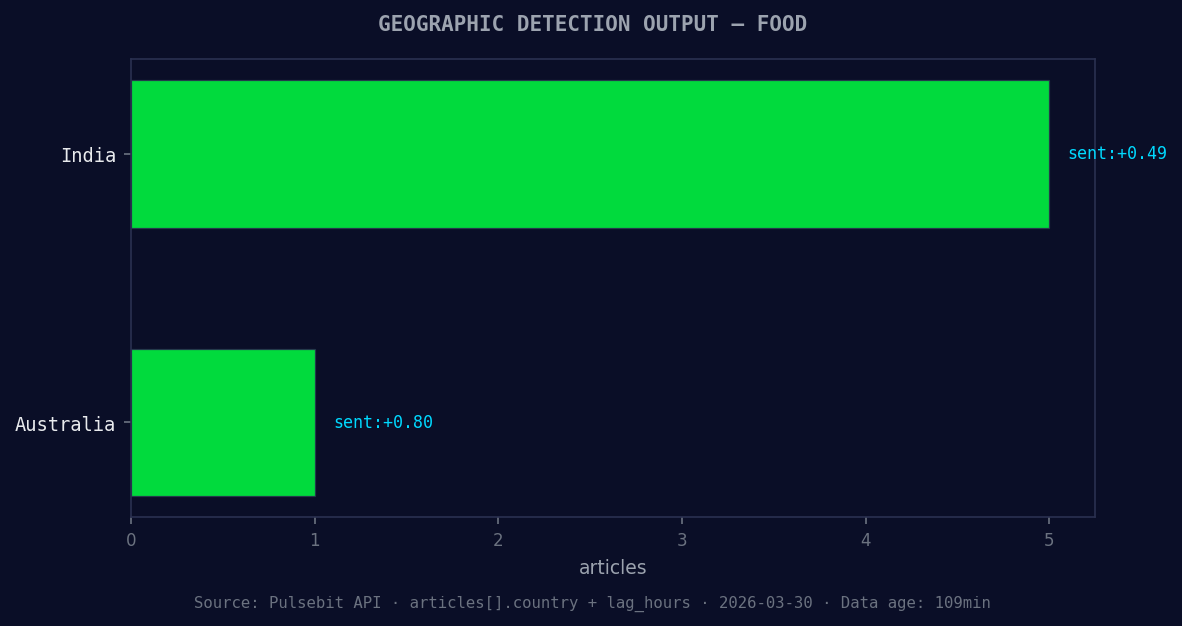
*Geographic detection output for food. India leads with 5 articles and sentiment +0.49. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Check the output for sentiment analysis
print(data)
Next, we need to run the cluster reason string through our sentiment endpoint to score the narrative framing itself. This helps us understand how the themes are perceived in the media.
# Meta-sentiment moment: scoring the cluster reason
cluster_reason = "Clustered by shared themes: hyderabad, police, tonnes, adulterated, food."
sentiment_url = 'https://api.pulsebit.com/v1/sentiment'
sentiment_response = requests.post(sentiment_url, json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
# Output the sentiment score for the cluster reason
print(sentiment_data)
This code snippet will give you insights into the media sentiment surrounding the Hyderabad police's actions regarding food safety.
Now, let’s explore three specific builds we can implement based on this momentum spike:
Geo-Filtered Alert System: Build a real-time alert system that triggers when sentiment drops below a certain threshold (e.g., -0.850) for specific topics like food. Use the geo filter to ensure you only capture relevant events in regions of interest.
Meta-Sentiment Analysis Tool: Create a tool that continuously analyzes cluster reasons and their sentiment scores. Use the meta-sentiment loop to score narratives weekly, helping you understand shifts in public perception around critical issues.
Forming Themes Dashboard: Develop a dashboard that visualizes forming themes like 'food' (+0.00), 'google' (+0.00), and 'fast' (+0.00) against mainstream topics like 'hyderabad', 'police', and 'tonnes'. This allows for quicker decision-making based on emerging narratives.
You can start implementing these ideas quickly. For detailed guidance, visit our documentation at pulsebit.lojenterprise.com/docs. We believe you can copy, paste, and run this in under 10 minutes, moving your analytics pipeline closer to real-time responsiveness.

Top comments (0)