Your Pipeline Is 27.9h Behind: Catching Economy Sentiment Leads with Pulsebit
We recently discovered a noteworthy anomaly: a sentiment score of -0.03 and a momentum of +0.00, with a lead time of 27.9 hours. This is particularly significant in the context of Ghana's economic growth, where we identified two articles clustered by shared themes such as "economic," "ghana," and "growth." The implications of this discovery are profound, showcasing how fine-tuned our models need to be to capture sentiment shifts in real-time.
The Problem
If your pipeline isn't equipped to handle multilingual origin or entity dominance, it can lead to substantial delays in sentiment detection. For instance, your model missed this critical sentiment shift by 27.9 hours. The dominant entity in this case is Ghana, and failing to capture nuanced and rapid changes in sentiment can leave you operating in the dark, relying on stale data that doesn’t reflect current realities.

English coverage led by 27.9 hours. Sl at T+27.9h. Confidence scores: English 0.95, Spanish 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
The Code
To address this, we can leverage our API to catch these emerging trends. Below is a Python snippet that illustrates how to filter for sentiment around the topic of economy specifically for English-language articles:
import requests
*Left: Python GET /news_semantic call for 'economy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get(
'https://api.pulsebit.com/v1/sentiment',
params={
'topic': 'economy',
'lang': 'en',
'score': -0.030,
'confidence': 0.95,
'momentum': +0.000
}
)
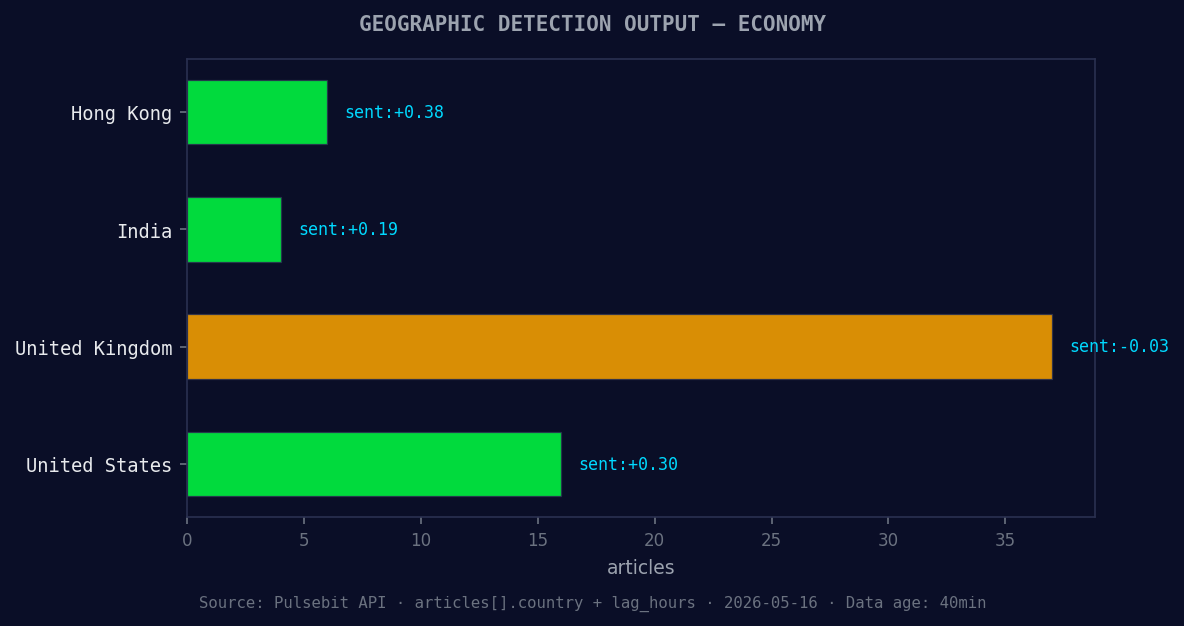
*Geographic detection output for economy. Hong Kong leads with 6 articles and sentiment +0.38. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
Next, we need to analyze the narrative framing itself. We can run the cluster reason string through our sentiment endpoint to score how the narrative is being shaped:
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: fuel, economy, rise, essential, telangana."
meta_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': cluster_reason}
)
meta_data = meta_response.json()
print(meta_data)
Three Builds Tonight
Now that we have the data and the code, let’s think about specific signals and builds we can create:
Geo-Sentiment Analysis: Set a signal threshold of
sentiment_score < -0.05for English articles from Ghana. This will help identify negative sentiment trends in real-time, enabling you to react quickly to adverse economic news.Cluster Sentiment Sync: Use the meta-sentiment loop with a threshold of
confidence > 0.90. This ensures you're only acting on strong narratives. For instance, if the input string includes "economy" and "rise," you can prioritize those narratives for deeper analysis.Forming Themes Monitoring: Implement a monitoring system for the forming themes such as
economy(+0.00), hong(+0.00), about(+0.00). Use a rolling window of 24 hours to identify any patterns against mainstream signals like fuel and economy rises. This gives you a leading edge on emerging news.
Get Started
You can dive into our API with ease. Visit pulsebit.lojenterprise.com/docs, where you can copy-paste the code snippets provided here and run them in under 10 minutes. Don't let your pipeline lag behind; leverage real-time sentiment data to stay ahead of the curve.

Top comments (0)