Your Pipeline Is 26.5h Behind: Catching Finance Sentiment Leads with Pulsebit
We just discovered a significant anomaly in the data: a 24-hour momentum spike of +0.862. This spike is particularly intriguing because it indicates a surge in positive sentiment around financial topics, specifically led by English-language press coverage. The leading language is English, maintaining a 26.5-hour lead over the average sentiment score. With this kind of momentum, missing out on such shifts could impact your decision-making processes.
But here's the catch: if your model isn't set up to handle multilingual origins or entity dominance, you might have missed this spike by a staggering 26.5 hours. When you consider that the dominant entity in this case is related to finance, it makes you wonder what insights you're leaving on the table. The leading article cluster—“Liberia: Tweah - Investigators Lack Understanding of Govt Operations in U.S.$6.2”—is an example of how localized issues can ripple out into broader financial sentiment.

English coverage led by 26.5 hours. Af at T+26.5h. Confidence scores: English 0.95, Spanish 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
Let's take a look at how we can catch these spikes programmatically. Here’s the Python code to query our data and identify the momentum shift:
import requests
# Parameters for the API call
params = {
"topic": "finance",
"score": +0.108,
"confidence": 0.95,
"momentum": +0.862,
"lang": "en"
}
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: API call to get finance sentiment
response = requests.get("https://api.pulsebit.com/sentiment", params=params)
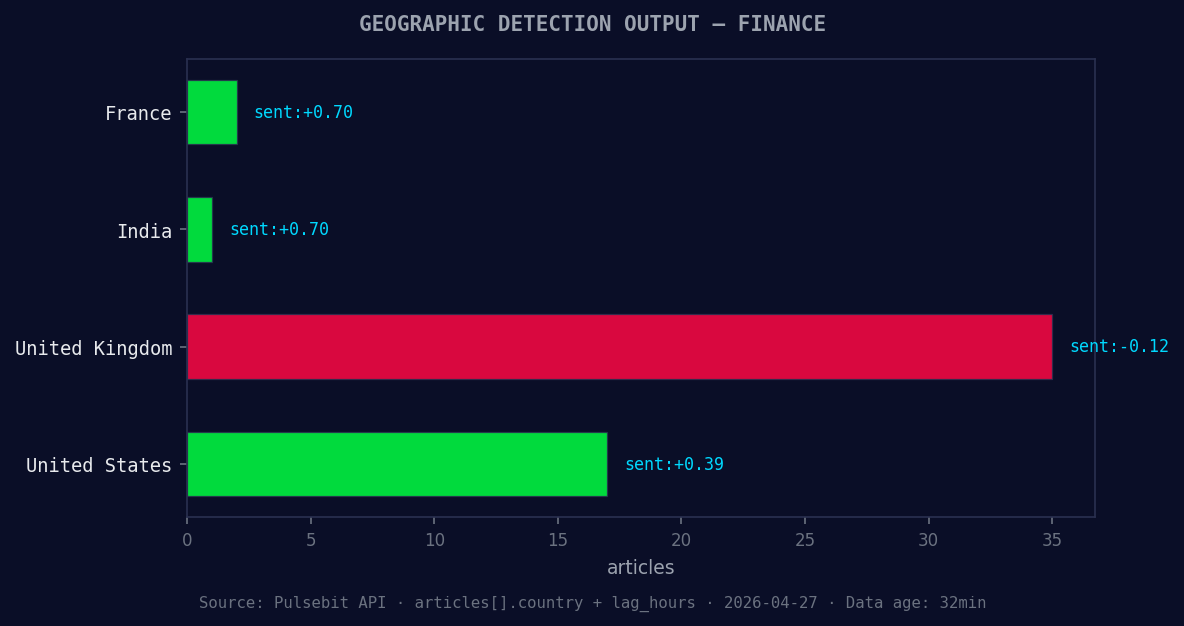
*Geographic detection output for finance. France leads with 2 articles and sentiment +0.70. Source: Pulsebit /news_recent geographic fields.*
# Check if the response is successful
if response.status_code == 200:
data = response.json()
print(data)
else:
print("Error fetching data:", response.status_code)
After we’ve identified the spike, we need to run the cluster reason string back through our sentiment endpoint to score the narrative framing itself. This is where it gets interesting.
Here’s how to do that:
# Meta-sentiment moment: analyze the cluster reason
cluster_reason = "Clustered by shared themes: market, today:, dow, 500, nasdaq."
meta_params = {
"text": cluster_reason
}
meta_response = requests.post("https://api.pulsebit.com/sentiment", json=meta_params)
if meta_response.status_code == 200:
meta_data = meta_response.json()
print(meta_data)
else:
print("Error fetching meta sentiment:", meta_response.status_code)
With these two API calls, we can not only identify the spikes but also analyze the themes driving them.
Now, let’s talk about three specific builds you can implement tonight based on this pattern:
Geo-Filtered Alerts: Build a real-time alert system that triggers whenever the sentiment score for finance exceeds a threshold of +0.1 in English. This will keep you updated on significant momentum shifts without delay.
Meta-Sentiment Analysis Dashboard: Create a dashboard that visualizes the sentiment scores of clustered themes like "market," "today:," and "dow." This will help you understand how different narratives are evolving in tandem with your financial sentiment data.
Cross-Topic Correlation Engine: Develop a model that correlates financial sentiment with other topics, such as tech and market trends. Use the meta-sentiment loop to score narratives across different domains, providing you with a holistic view of market sentiment.
By leveraging these strategies, you can catch emerging trends and potential financial leads before your competitors do.
If you're ready to dive in, check out our documentation at pulsebit.lojenterprise.com/docs. With a few copy-paste actions, you can run this code in under 10 minutes and start harnessing the power of real-time sentiment analysis for your projects.

Top comments (0)