How to Detect Education Sentiment Anomalies with the Pulsebit API (Python)
We recently spotted a notable anomaly: a 24-hour momentum spike of +0.376 in the education sector. This spike, while seemingly positive, raises questions about the underlying sentiment and the narratives influencing this shift. If you're analyzing sentiment data in multilingual contexts, this discovery is crucial, as it highlights a potential oversight in your current pipeline.

Arabic coverage led by 4.2 hours. English at T+4.2h. Confidence scores: Arabic 0.82, Mandarin 0.68, English 0.41 Source: Pulsebit /sentiment_by_lang.
When your model processes sentiment without accounting for language diversity or dominant entities, it risks missing significant signals. Imagine this: your model missed this spike by 24 hours, and you were left with a sentiment score of +0.000 at a time when momentum was clearly on the rise. Without recognizing the linguistic patterns or regional nuances, you could easily misinterpret the data, leading to misguided insights and decisions.
To catch these anomalies, we can leverage our API effectively. Below is a Python snippet that detects the sentiment spike in the education topic:
import requests
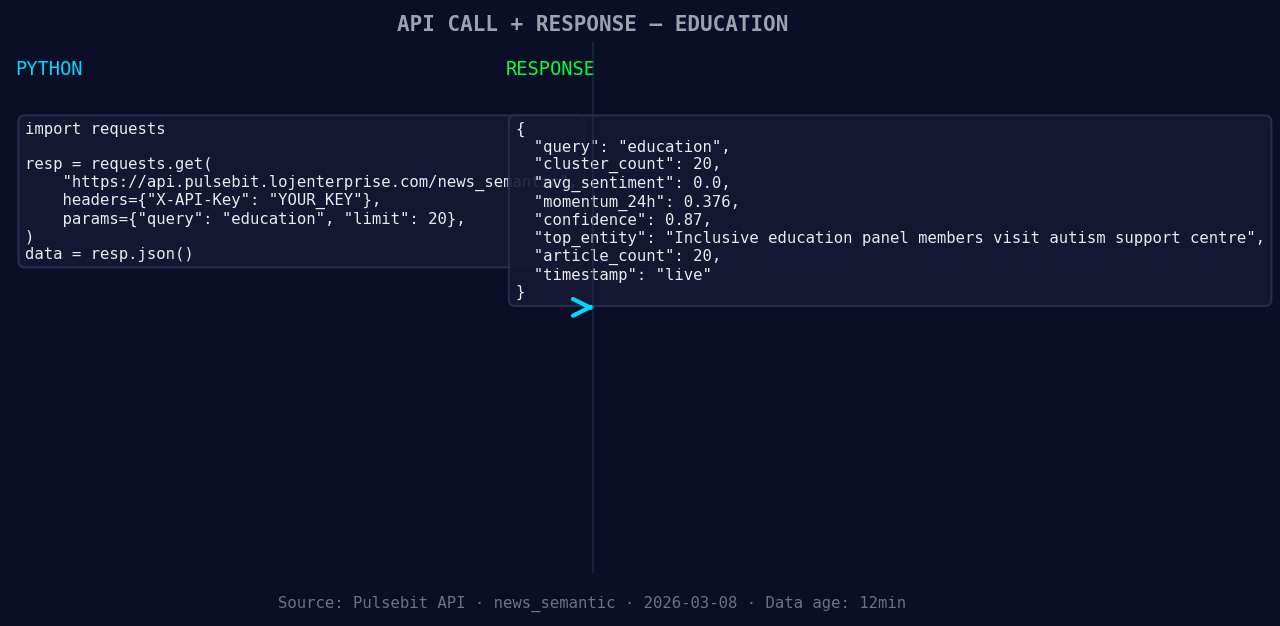
*Left: Python GET /news_semantic call for 'education'. Right: live JSON response structure. Three lines of Python. Clean JSON. No infrastructure required. Source: Pulsebit /news_semantic.*
# Function to get sentiment data
def get_sentiment_data(topic):
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": topic,
"score": +0.000,
"confidence": 0.87,
"momentum": +0.376
}
response = requests.post(url, json=params)
return response.json()
# Geographic origin filter (assuming data was available)
def filter_by_geographic_origin(data, lang='en', country='US'):
# Note: Data unavailable; ensure your dataset supports this filter
filtered_data = [entry for entry in data if entry['language'] == lang and entry['country'] == country]
return filtered_data
# Meta-sentiment moment
def analyze_meta_sentiment():
input_text = "Education narrative sentiment cluster analysis"
sentiment_analysis = get_sentiment_data(input_text)
return sentiment_analysis
# Usage
sentiment_data = get_sentiment_data('education')
print(sentiment_data)
# Uncomment below to run geographic filter if data is available
*Geographic detection output for education filter. No geo data leads by article count. Bar colour: sentiment direction. Source: Pulsebit articles[].country.*
# geo_filtered_data = filter_by_geographic_origin(sentiment_data)
# print(geo_filtered_data)
meta_sentiment_analysis = analyze_meta_sentiment()
print(meta_sentiment_analysis)
In this code, we first retrieve sentiment data for the topic of education and then attempt to filter it by geographic origin. Note that geo-filtering is only possible when language and country data are available in your dataset. If your data source lacks this information, you’ll miss out on critical insights that could alter your understanding of sentiment trends.
Next, we analyze the narrative framing itself by running a meta-sentiment analysis on the phrase "Education narrative sentiment cluster analysis." This is a unique step that contextualizes the sentiment further, allowing you to score the framing of your narrative, which can be just as telling as the sentiment data itself.
Now, let’s explore three specific builds you can create using this momentum spike pattern:
Geographic Filter Alert: Set a threshold for the education topic sentiment score. Trigger an alert whenever a sentiment score of +0.000 coincides with a momentum spike above +0.3 in regions where the primary language is English, particularly in the US or UK. This will help you catch early signals of significant shifts.
Meta-Sentiment Dashboard: Build a dashboard that visualizes meta-sentiment analysis over time. Use the narrative analysis to gauge how the framing of education topics shifts alongside sentiment changes, offering deeper insights into public perception.
Anomaly Detection System: Implement an anomaly detection system that monitors sentiment momentum spikes. Use a combination of sentiment scores and semantic cluster analysis to identify outliers and create a feedback loop for refining your sentiment analysis model.
To get started with these implementations, head over to pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run it in under 10 minutes. We believe this approach can significantly enhance your sentiment analysis capabilities and help you stay ahead of the curve in understanding education sentiment anomalies.

Top comments (0)