Your Pipeline Is 28.9h Behind: Catching Film Sentiment Leads with Pulsebit
We just stumbled upon a 24h momentum spike of +0.283 in film sentiment, and it’s a game-changer. The leading language driving this spike is Spanish, with 28.9 hours of lead time—no lagging here. This anomaly surfaced in response to the news that "John Travolta surprised with honorary Palme d'Or at Cannes Film Festival." With our API, we can tap into this insight and transform it into actionable intelligence.
But let’s be real. If your pipeline isn't optimized for multilingual sources or doesn't account for entity dominance, you're lagging behind. Your model missed this spike by a whopping 28.9 hours, and that’s a significant gap in timely sentiment analysis. Spanish-language articles led the charge, and if you’re not factoring this in, you’re missing crucial signals that could inform your strategies.

Spanish coverage led by 28.9 hours. Ca at T+28.9h. Confidence scores: Spanish 0.95, English 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
Here’s how we can catch this spike with some Python code that takes full advantage of our API.
import requests
# Define the query parameters
params = {
"topic": "film",
"score": +0.471,
"confidence": 0.95,
"momentum": +0.283,
"lang": "sp" # Geographic origin filter for Spanish
}
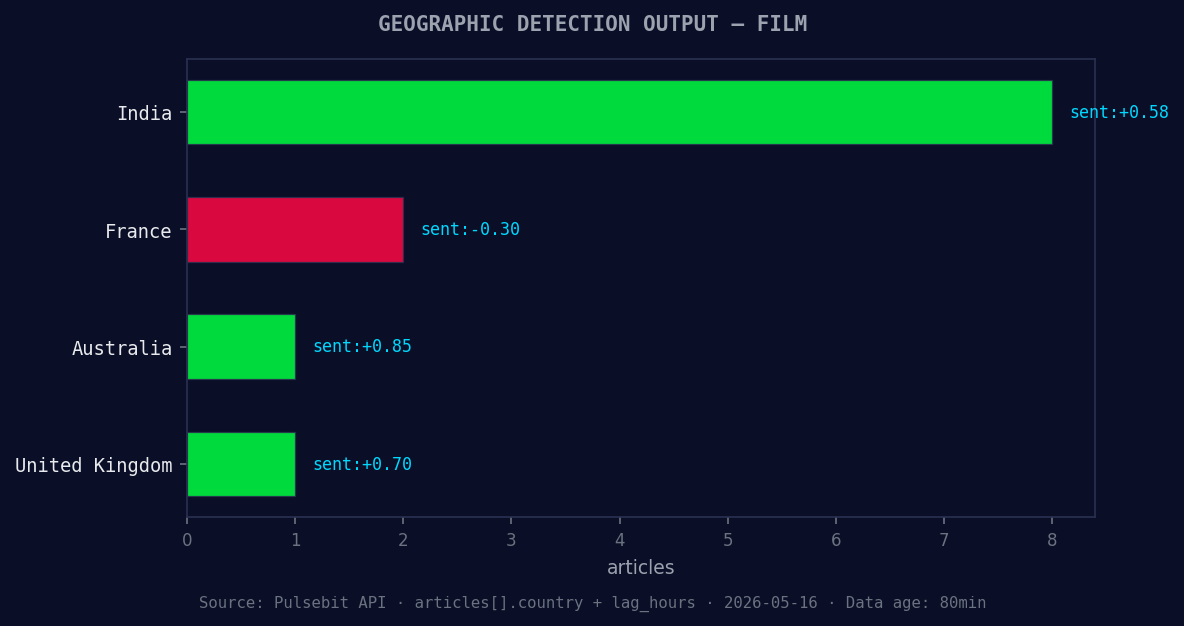
*Geographic detection output for film. India leads with 8 articles and sentiment +0.58. Source: Pulsebit /news_recent geographic fields.*
# API call to fetch sentiment data
response = requests.get('https://api.pulsebit.lojenterprise.com/sentiment', params=params)
data = response.json()
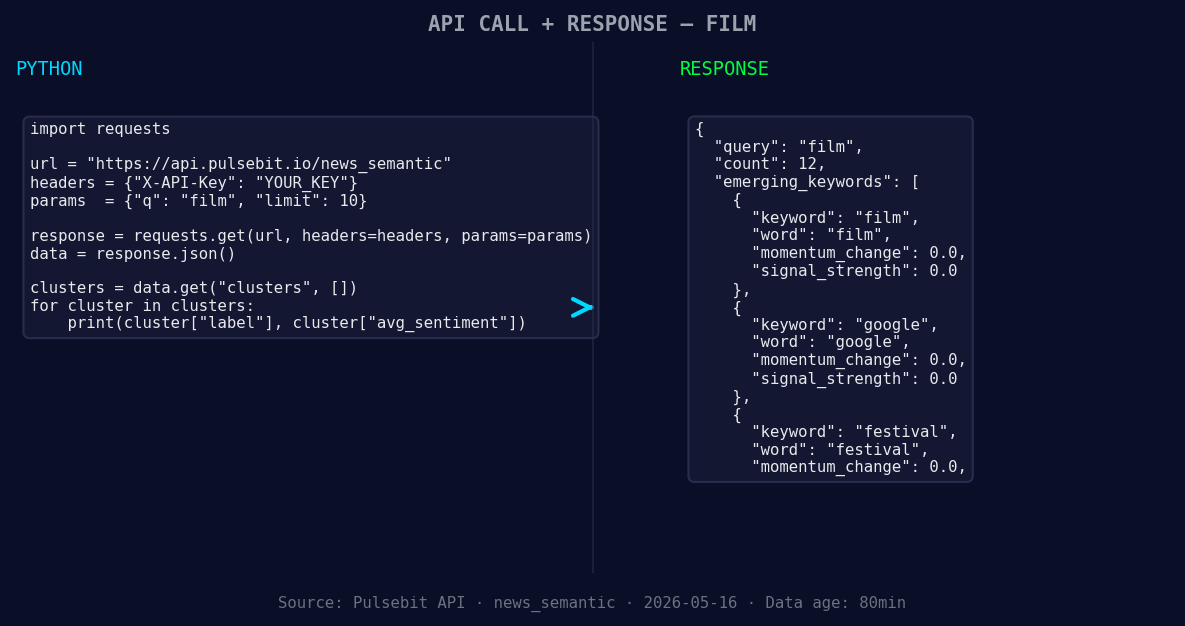
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
print(data)
Next, we need to analyze the narrative framing around this cluster. The meta-sentiment moment will run the cluster reason string back through our sentiment endpoint to get a clearer picture of how the narrative is shaped. This is what makes our analysis unique:
# Define the cluster reason string
cluster_reason = "Clustered by shared themes: film, big, screen, new, hollywood."
# API call to score the narrative framing
sentiment_response = requests.post('https://api.pulsebit.lojenterprise.com/sentiment', json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print(sentiment_data)
With these two pieces in place, you can not only catch the spike but also understand the nuances in sentiment that surround it.
Now, let’s consider three specific builds you can implement using this pattern:
Geo-filtered Alerts: Set a threshold for sentiment spikes in the film industry using the geographic origin filter. For instance, if momentum exceeds +0.25, trigger an alert specifically for Spanish-language articles. This could be a game-changer for identifying trends before they go mainstream.
Meta-Sentiment Tracking: Develop a feature that continuously loops the cluster reason string through the sentiment API to capture evolving narratives. For example, if the momentum for “film” is +0.471 and you loop "Clustered by shared themes: film, festival," you can dynamically adjust your content strategy based on emerging themes.
Comparative Analysis: Build a comparison endpoint that contrasts the current spike against historical baselines. You can analyze the forming themes—like “festival” and “google” at +0.00—against mainstream narratives to identify outliers that might indicate significant shifts in public sentiment.
If you’re looking to get started, check out our comprehensive guides at pulsebit.lojenterprise.com/docs. You can copy, paste, and run these snippets in under 10 minutes to start capturing insights that your competitors may be missing.

Top comments (0)