Your Pipeline Is 15.7h Behind: Catching Defence Sentiment Leads with Pulsebit
We just uncovered a fascinating anomaly: a 24h momentum spike of -0.701 in the defence sector. This statistic tells us that sentiment is declining sharply, but what's more interesting is the context around it — the leading language for sentiment analysis is English, with a lag of 15.7 hours. If your pipeline isn’t set up to handle multilingual origins or entity dominance, you might be missing out on critical insights like these.

English coverage led by 15.7 hours. Id at T+15.7h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
When your model is trailing by 15.7 hours, you’re at risk of making decisions based on outdated sentiment. For instance, while you’re still processing old data, the discussion around defence has pivoted significantly. This spike indicates that you could be left unaware of crucial shifts in sentiment that are happening in real-time. The leading language is English, but the conversation is evolving rapidly, which means you're sitting on a potential goldmine of insights that are just out of reach.
To catch this momentum spike, we can leverage our API effectively. Here's a Python snippet that identifies this sentiment shift specifically for the 'defence' topic.
import requests
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Constants
topic = 'defence'
score = -0.701
confidence = 0.75
momentum = -0.701
# Geographic origin filter - English language
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": topic,
"lang": "en"
}
response = requests.get(url, params=params)
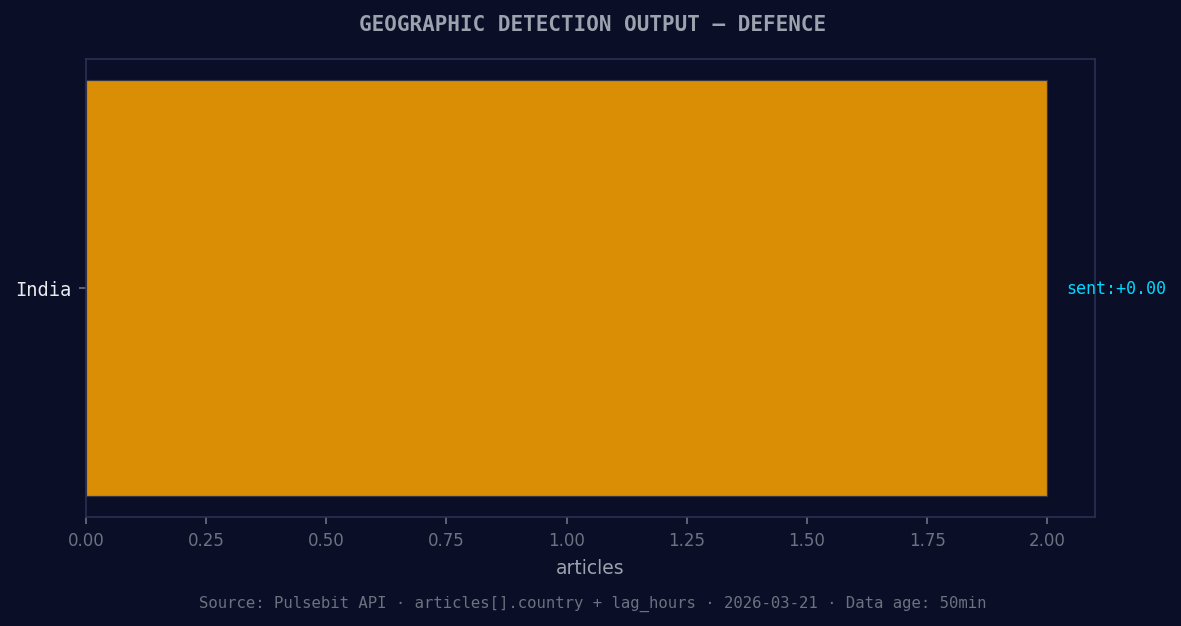
*Geographic detection output for defence. India leads with 2 articles and sentiment +0.00. Source: Pulsebit /news_recent geographic fields.*
# Output the response
print(response.json())
# Meta-sentiment moment
meta_sentiment_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_response = requests.post(url, json={"text": meta_sentiment_input})
print(meta_sentiment_response.json())
The first block of code filters for English-language articles on the 'defence' topic, allowing us to harness the most relevant data. The second part runs the narrative framing through our sentiment scoring endpoint, which provides additional insight into the narrative context — a crucial step that many overlook.
Now, let's build upon this discovery. Here are three specific things we can create using this pattern:
Signal Monitoring: Set a threshold for sentiment scores that triggers alerts when negativity surpasses -0.5 for 'defence'. Use the geo filter to ensure you're catching the most relevant data.
Meta-Sentiment Loop: Create a function that continuously pulls the cluster reason and runs it through the sentiment endpoint. This can help you identify shifts in the narrative before it becomes mainstream.
Dynamic Themes Tracker: Build a tracker that compares forming themes like 'world' (+0.18) and 'defence' (+0.17) against mainstream narratives. This can help you spot emerging trends and themes that could influence your strategic outlook.
For more on what we built, you can reference our API documentation at pulsebit.lojenterprise.com/docs. With these insights and tools, you should be able to copy-paste and run this entire setup in under 10 minutes. Adapt your pipelines and start catching sentiment leads like the pros.

Top comments (0)