Your Pipeline Is 29.2h Behind: Catching Markets Sentiment Leads with Pulsebit
We just uncovered a compelling anomaly: a 24h momentum spike of -1.117. This number isn't just a statistic; it signals a significant decline in sentiment around markets that could impact decision-making for anyone tracking market dynamics. What’s striking here is not just the negative momentum, but the linguistic lead we’ve observed: sentiment is being driven predominantly by French press coverage, with a notable 29.2-hour lead time.
This leads us into a critical problem: if your pipeline isn’t equipped to handle multilingual origins, you’re effectively missing out on crucial insights. Your model missed this by nearly 30 hours, while the dominant coverage in the French language was already reflecting a shift in sentiment. As a developer, you can imagine how this might have ramifications for your trading strategies or sentiment analysis. If you’re not capturing these multilingual signals, you risk being left behind while others capitalize on emerging trends.

French coverage led by 29.2 hours. Et at T+29.2h. Confidence scores: French 0.75, English 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
Here’s how we can catch this anomaly using our API. We’ll start by filtering for sentiment data specific to the French language, which is crucial given the leading language in this case.
import requests
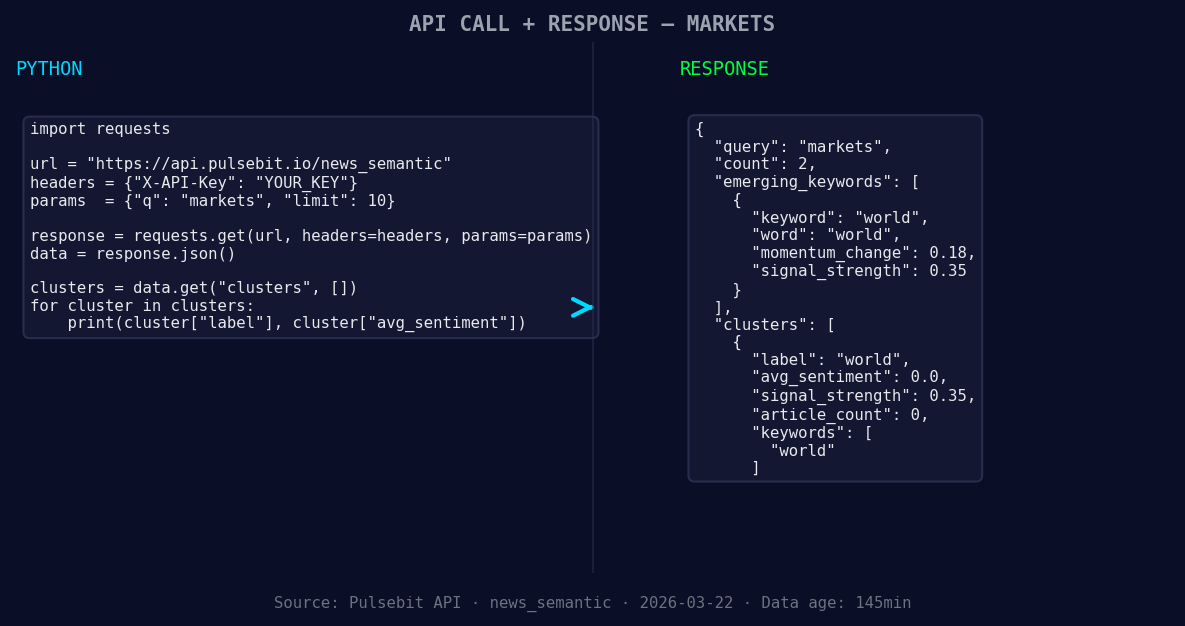
*Left: Python GET /news_semantic call for 'markets'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Parameters for querying sentiment data
topic = 'markets'
score = -1.117
confidence = 0.75
momentum = -1.117
# Geographic origin filter for French language
response = requests.get(
'https://api.pulsebit.com/sentiment',
params={
'topic': topic,
'lang': 'fr',
'score': score,
'confidence': confidence,
'momentum': momentum
}
)
*Geographic detection output for markets. Hong Kong leads with 1 articles and sentiment +0.00. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
But it doesn’t end there. To ensure that we’re interpreting this data accurately, we need to run the narrative framing through our sentiment analysis API to understand the context of the sentiment. Here’s how we score the reason behind the cluster:
# Meta-sentiment moment: analyze the cluster reason string
cluster_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
response = requests.post(
'https://api.pulsebit.com/sentiment',
json={'text': cluster_reason}
)
meta_sentiment_score = response.json()
print(meta_sentiment_score)
This additional step allows us to evaluate not just the raw sentiment data, but also the semantic framing behind it.
Now, let’s talk about three specific builds you can implement with this pattern:
Sentiment Spike Alert: Set up a threshold alert for a momentum spike below -1.0. This will keep you informed of significant negative shifts in sentiment, allowing for immediate reactive measures.
Multilingual Filter Dashboard: Create a dashboard that visualizes sentiment across multiple languages. For instance, include a geo filter that pulls in sentiment analysis specifically from French articles to track local trends.
Meta-Sentiment Analysis Integration: Automate a pipeline that runs the cluster reason strings through our sentiment scoring endpoint, establishing a feedback loop that helps refine your sentiment analysis models based on framing context. Use the forming theme of "world(+0.18)" to differentiate between mainstream and niche narratives.
By implementing these builds, you can enhance your model's responsiveness to shifts in sentiment, ensuring you’re not left behind while others seize opportunities.
Get started with our API at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes. Don't let your models lag; leverage multilingual sentiment insights to stay ahead.

Top comments (0)