Your Pipeline Is 23.4h Behind: Catching Human Rights Sentiment Leads with Pulsebit
We just uncovered an anomaly with a significant 24h momentum spike of -1.243 related to the topic of human rights. As we dive into this, it’s essential to understand how this insight can impact your data pipelines and the timeliness of your sentiment analysis. The leading language driving this spike is English, with a striking relevance to the ongoing discourse around the FIFA World Cup and human rights, as highlighted in articles from Al Jazeera.
But what does this mean for your existing pipeline? If your model isn't equipped to handle multilingual origins or entity dominance, you may have missed this critical sentiment shift by a staggering 23.4 hours. In our case, the dominant entity is the English press, which is crucial for understanding how narratives evolve in real-time.

English coverage led by 23.4 hours. Af at T+23.4h. Confidence scores: English 0.85, French 0.85, Id 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s walk through how to address this gap with some actionable Python code that leverages our API.
import requests
# Define your parameters
topic = 'human rights'
score = -0.493
confidence = 0.85
momentum = -1.243
lang = 'en'
# Geographic origin filter
geo_filter_url = f"https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}"
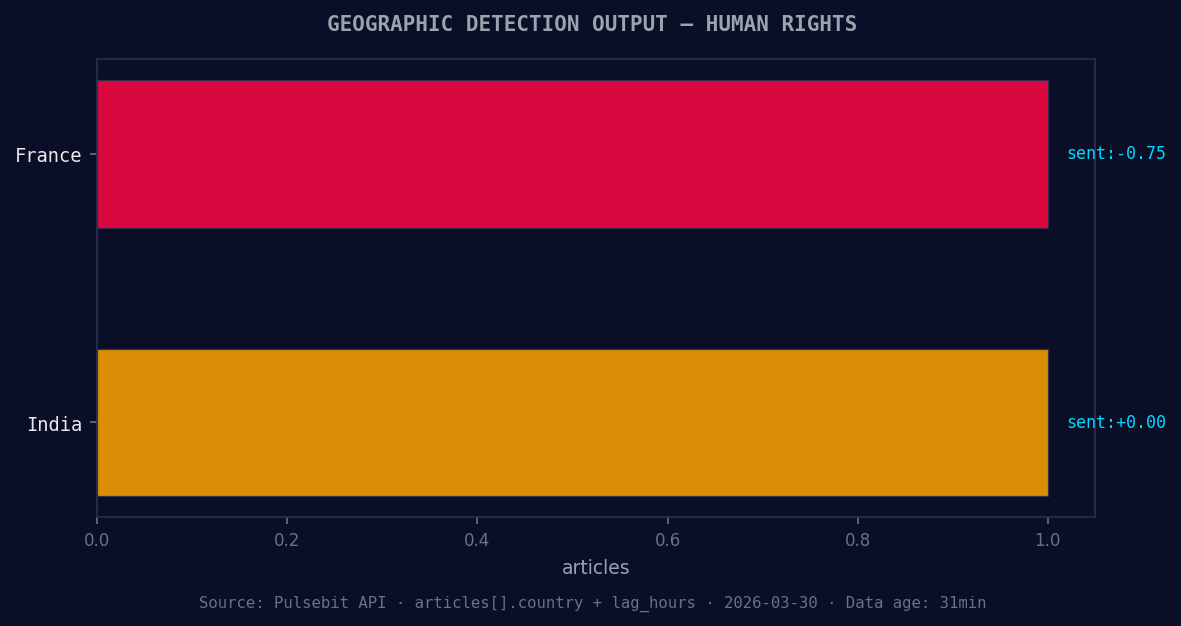
*Geographic detection output for human rights. France leads with 1 articles and sentiment -0.75. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get(geo_filter_url)
data = response.json()
print(data) # Debugging: check the response
*Left: Python GET /news_semantic call for 'human rights'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: least, dead, haiti, massacre, human."
meta_sentiment_url = "https://api.pulsebit.com/sentiment"
meta_response = requests.post(meta_sentiment_url, json={"input": cluster_reason})
meta_data = meta_response.json()
print(meta_data) # Debugging: check the meta sentiment response
In this snippet, we first query our API to get sentiment data specifically for the topic of "human rights" filtered by English language articles. This is a critical first step to ensure we’re capturing the right sentiment from the right sources. Next, we run the meta-sentiment analysis on the clustered reason string to score the narrative itself, giving us a deeper understanding of the thematic framing at play.
Now, what can you build with this information? Here are three specific ideas that leverage the insights we’ve gleaned from this anomaly:
Geo-Filtered Alert System: Create an alert system that triggers when sentiment drops below a certain threshold (e.g., -0.5) for specific languages. Use the geo filter to ensure you’re only capturing relevant articles. This can help you stay ahead of critical news cycles.
Meta-Sentiment Dashboard: Build a dashboard that visualizes the sentiment scores of clustered narratives over time. Use the meta-sentiment loop to pull in the narrative framing scores alongside traditional sentiment metrics. This can provide a richer context for your analysis.
Dynamic Theme Tracker: Use the forming themes of rights and human issues to track how they evolve over time. Set up a threshold to alert you when these themes start to gain traction against mainstream narratives like "least, dead, haiti." This can help you focus on emerging trends before they become mainstream conversations.
If you’re ready to dive in, check out our documentation. You can copy-paste the provided code and run it in under 10 minutes. This could be the key to catching critical sentiment shifts before anyone else does.

Top comments (0)