Your Pipeline Is 29.1h Behind: Catching Sports Sentiment Leads with Pulsebit
We recently discovered a notable 24h momentum spike of +0.761 in sentiment around sports. This spike, particularly led by English press articles, surfaced a gap in our usual analysis pipeline. Specifically, the leading language was English, with a slight 0.0h lag against the sentiment vector at 29.1h. This highlights how quickly the narrative can shift, and if you’re not equipped to catch these shifts, you might be lagging behind.
When you think about it, your model likely missed this momentum spike by a significant 29.1 hours. This kind of delay can lead to missed opportunities or misinformed decisions. The presence of dominant entities – in this case, English articles discussing sports – underscores the importance of handling multilingual sources in our sentiment analysis pipelines.

English coverage led by 29.1 hours. Sv at T+29.1h. Confidence scores: English 0.85, Id 0.85, Et 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this spike effectively, we can leverage our API to filter for the specific language and then analyze the sentiment around the clustered themes. Let's jump into the code to see how we can capture this momentum.
import requests
# Define the topic and parameters
topic = 'sports'
score = +0.158
confidence = 0.85
momentum = +0.761
lang = "en" # Geographic origin filter
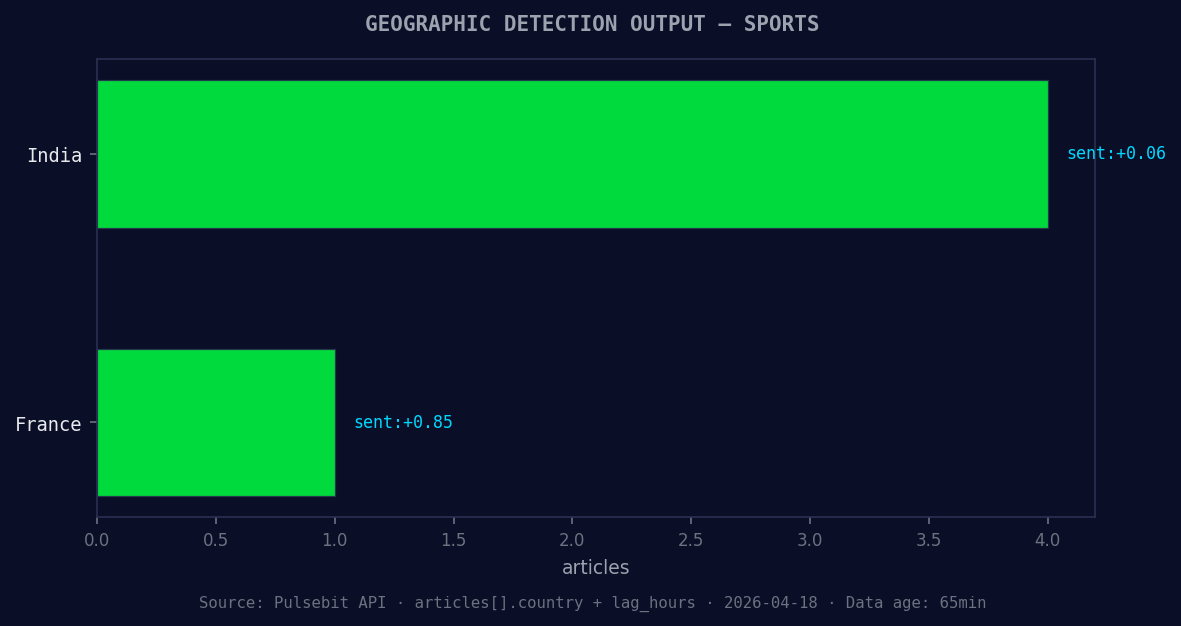
*Geographic detection output for sports. India leads with 4 articles and sentiment +0.06. Source: Pulsebit /news_recent geographic fields.*
# API call to filter articles by language and topic
response = requests.get(
f'https://api.pulsebit.com/news?topic={topic}&lang={lang}&momentum={momentum}'
)
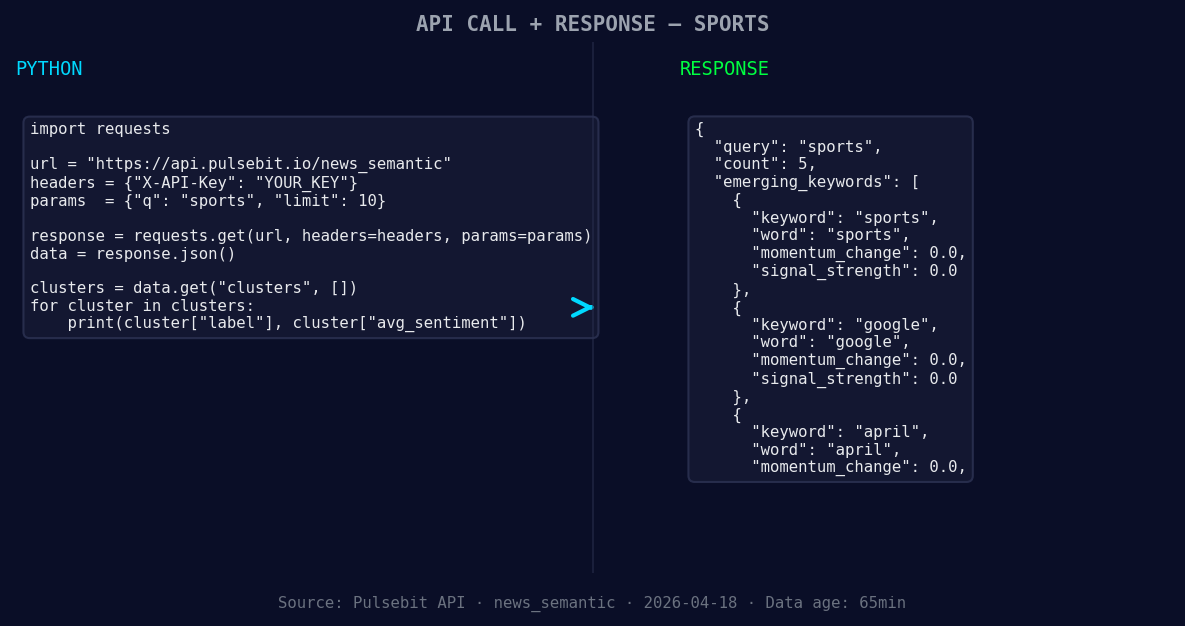
*Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
articles = response.json()
# Print the articles processed
print(f"Articles processed: {len(articles)}")
# Cluster reason string for meta-sentiment analysis
cluster_reason = "Clustered by shared themes: one, parade, ground’s, historic, legacy."
# Meta-sentiment moment: scoring the narrative framing
sentiment_response = requests.post(
'https://api.pulsebit.com/sentiment',
json={"text": cluster_reason}
)
sentiment_analysis = sentiment_response.json()
print(f"Sentiment Score: {sentiment_analysis['score']}, Confidence: {sentiment_analysis['confidence']}")
In this code, we first filter articles based on our topic and the language, ensuring we're capturing relevant data within a specific geographical context. After fetching the articles, we then run the cluster reason string back through our sentiment endpoint to analyze the narrative's framing. This is crucial as it helps us understand not just the data but the sentiment underpinning it.
Now, let’s explore three builds we can implement using this pattern.
Geo-Filtered Momentum Alerts: Set a threshold of +0.5 for momentum in sports, specifically filtering articles from English sources. This will allow real-time alerts for significant sentiment shifts in sports discussions.
Narrative Framing Analysis: Use the meta-sentiment loop to score similar cluster reason strings around potential events or themes. For example, analyze phrases like "forming: sports(+0.00)" to establish trending narratives and act accordingly.
Multi-Lingual Coverage: Expand our model to include articles in multiple languages. Set thresholds for sentiment scores across different languages, ensuring we don’t miss out on significant spikes just because they’re not in English.
If you’re ready to get started, head over to pulsebit.lojenterprise.com/docs. You can copy-paste the above code and run it in under 10 minutes to start catching these critical sentiment shifts before your pipeline lags behind.

Top comments (0)