Your 24-hour momentum spike of +0.262 in economic sentiment is a pivotal finding. It highlights a significant shift in how the global narrative is framing economic issues, particularly in relation to recent geopolitical events. The leading language in this spike is English, with a notable 12.5-hour lead. The cluster story that has emerged is about Pakistan's Prime Minister forming a crisis team to address the economic impacts of the West Asia conflict. This single article encapsulates the growing concern over economic stability in the region, revealing a critical point of interest for sentiment analysis.
The structural gap in your pipeline becomes evident here. If your model does not account for multilingual origins or entity dominance, you could have missed this spike by 12.5 hours. The dominant entity, Pakistan, and its response to geopolitical tensions are driving the sentiment shift. If your model only processes data in a narrow bandwidth, you risk being out of sync with the sentiment landscape, leading to missed opportunities.

English coverage led by 12.5 hours. Nl at T+12.5h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly efficiently, we can leverage our API. Here’s a Python snippet that demonstrates how to pull this relevant data:
import requests
*Left: Python GET /news_semantic call for 'economy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/endpoint"
params = {
"topic": "economy",
"lang": "en",
"momentum": "+0.262",
}
response = requests.get(url, params=params)
data = response.json()
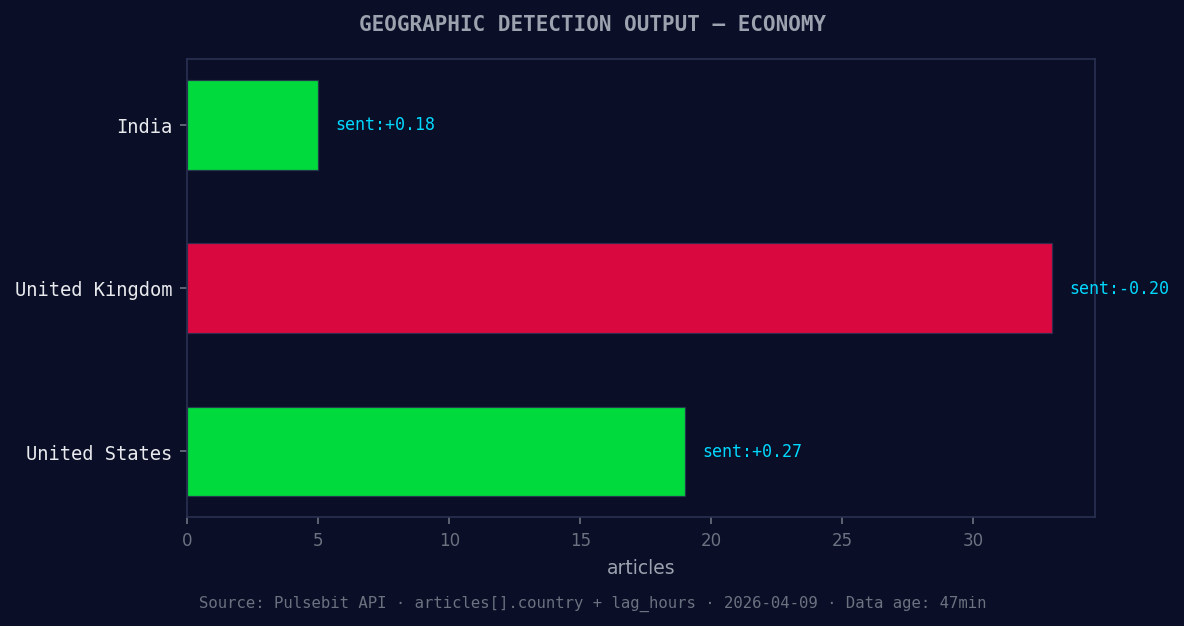
*Geographic detection output for economy. India leads with 5 articles and sentiment +0.18. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: management, pakistan, forms, crisis, team."
sentiment_payload = {"text": cluster_reason}
sentiment_response = requests.post("https://api.pulsebit.com/sentiment", json=sentiment_payload)
sentiment_data = sentiment_response.json()
print(data)
print(sentiment_data)
This code first filters for English-language articles related to the economy with a momentum of +0.262, then it scores the narrative framing of the clustered themes. This approach allows us to understand not just the sentiment but also the narrative context driving that sentiment.
Now, let’s discuss three specific builds you can implement using this newfound pattern:
Geo-Filtered Economic Monitor: Set a signal threshold for economic articles in English with a minimum sentiment score of +0.075. Use the geo filter to specifically target regions like Pakistan where the momentum change is significant. This can help in tracking localized economic sentiment shifts.
Meta-Sentiment Analyzer: Create a function that takes cluster reason strings and feeds them through our sentiment endpoint. Set an alert if the returned sentiment score is below a certain threshold. For example, if the sentiment from the string "Clustered by shared themes: management, pakistan, forms, crisis, team." drops below +0.050, notify your team for further investigation.
Sentiment vs. Mainstream Gap Analysis: Build a dashboard that compares forming themes, such as economy (+0.00), Google (+0.00), and war (+0.00), against mainstream themes like management, Pakistan, and forms. Set parameters to flag significant deviations in sentiment scores, helping you identify potential emerging stories before they become mainstream.
For a comprehensive guide to get started with these functionalities, visit pulsebit.lojenterprise.com/docs. You can copy-paste and run the provided code in under 10 minutes, allowing you to tap into the power of sentiment analysis effectively.

Top comments (0)