Your Pipeline Is 26.6h Behind: Catching Economy Sentiment Leads with Pulsebit
We've just hit a notable anomaly: a 24h momentum spike of +0.330 in economic sentiment. This spike not only reflects increased interest but also highlights a potential gap in our data pipelines. It’s essential to recognize these shifts as they can guide decision-making in real-time. The leading language contributing to this spike is English, with a specific focus on the economic narratives shaping our markets.
The Problem
If your model doesn’t account for multilingual origins or entity dominance, you might find yourself missing critical insights. In this case, your pipeline is lagging by 26.6 hours behind the sentiment shift generated by the English press. This delay could lead to significant missed opportunities, especially given that the dominant narrative revolves around economic topics, which are currently experiencing a rising trend.

English coverage led by 26.6 hours. Et at T+26.6h. Confidence scores: English 0.90, French 0.90, Spanish 0.90 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this momentum spike effectively, we can leverage our API to filter by language and score the sentiment around clustered narratives. Here's how you can set this up in Python:
import requests
*Left: Python GET /news_semantic call for 'economy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.lojenterprise.com/v1/sentiment"
params = {
"topic": "economy",
"score": +0.042,
"confidence": 0.90,
"momentum": +0.330,
"lang": "en" # Filter by English
}
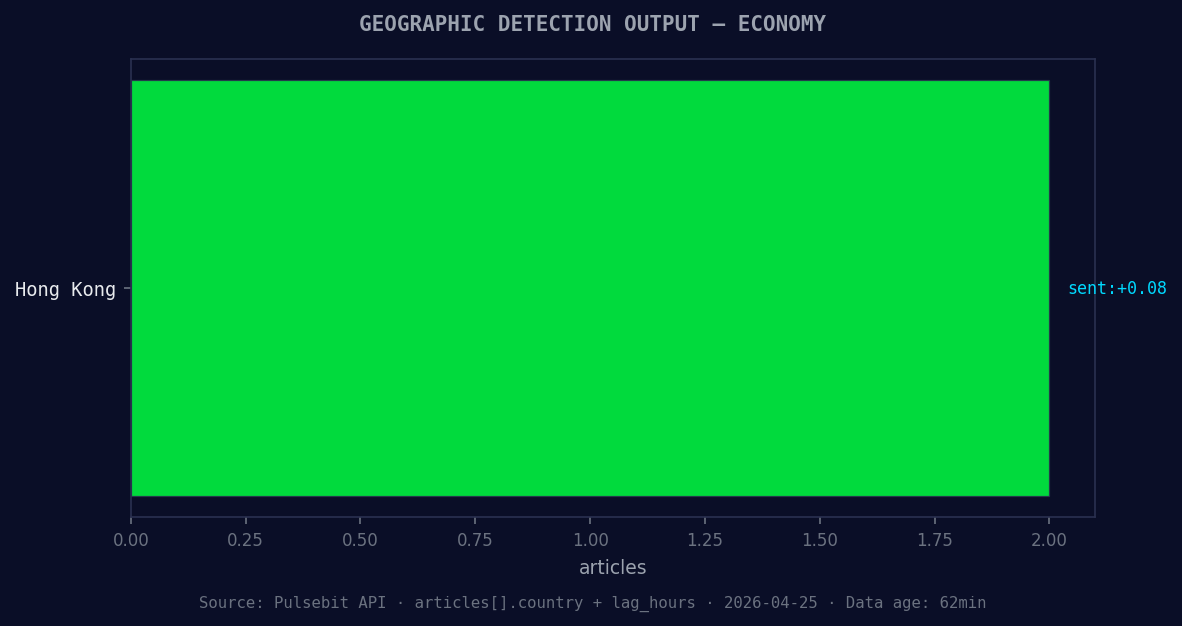
*Geographic detection output for economy. Hong Kong leads with 2 articles and sentiment +0.08. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
After we get the initial sentiment data, we can delve deeper into the narrative itself. Here’s how to run the cluster reason string through our sentiment analysis endpoint:
# Step 2: Meta-sentiment moment
meta_sentiment_url = "https://api.pulsebit.lojenterprise.com/v1/sentiment"
meta_input = {
"text": "Clustered by shared themes: economy, federal, reserve, capital, better."
}
meta_response = requests.post(meta_sentiment_url, json=meta_input)
meta_data = meta_response.json()
print(meta_data)
This approach not only highlights the current sentiment but also provides context around the themes driving the narrative, ensuring we’re not just reacting to surface-level data.
Three Builds Tonight
Now that you have this foundation, here are three specific builds you can implement using this momentum spike:
Geo-Filtered Alerts: Set up an alert system that triggers whenever the sentiment score for "economy" exceeds a threshold of +0.042 in English-language articles. This real-time monitoring can keep you ahead of critical developments.
Meta-Sentiment Dashboard: Create a dashboard that visualizes the meta-sentiment scores derived from narratives like "Clustered by shared themes: economy, federal, reserve, capital, better." This dashboard can help in understanding the framing of economic news and its potential impact.
Forming Themes Tracker: Develop a signal for emerging themes, such as "forming: economy(+0.00), google(+0.00), iran(+0.00)." This can help in identifying shifts in interest before they fully materialize in mainstream coverage, giving you an edge in anticipating market movements.
Get Started
To dive into this and start building your own implementations, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the above code snippets and have everything running in under 10 minutes. Don't let your pipeline fall behind!

Top comments (0)