Your Pipeline Is 22.9h Behind: Catching Finance Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24h momentum spike of -1.287 in the finance sector. This stark drop in sentiment is particularly telling, considering that the leading language driving this sentiment is Spanish, with a cluster story focused on "Johannesburg's Financial Crisis Amid Executive Pay." In a world where financial news can shift rapidly, this spike signals that there's more beneath the surface, and it’s essential to catch these trends before they become mainstream.
The problem here is clear: if your pipeline doesn’t consider multilingual origins or entity dominance, you could be lagging behind by 22.9 hours. While you were busy processing English-language articles, significant shifts in sentiment were brewing in the Spanish press. This gap is critical; it’s about being ahead of the curve, especially when the leading language is Spanish and the topic is as sensitive as financial crises. If you’re relying solely on a monolingual approach, you might miss key insights while your competitors are already acting on them.

Spanish coverage led by 22.9 hours. Et at T+22.9h. Confidence scores: Spanish 0.95, English 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can utilize our API effectively. Here’s how you can implement it in Python to filter out relevant data based on language and analyze sentiment clusters.
import requests
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get('https://api.pulsebit.com/sentiment', params={
'topic': 'finance',
'lang': 'sp'
})
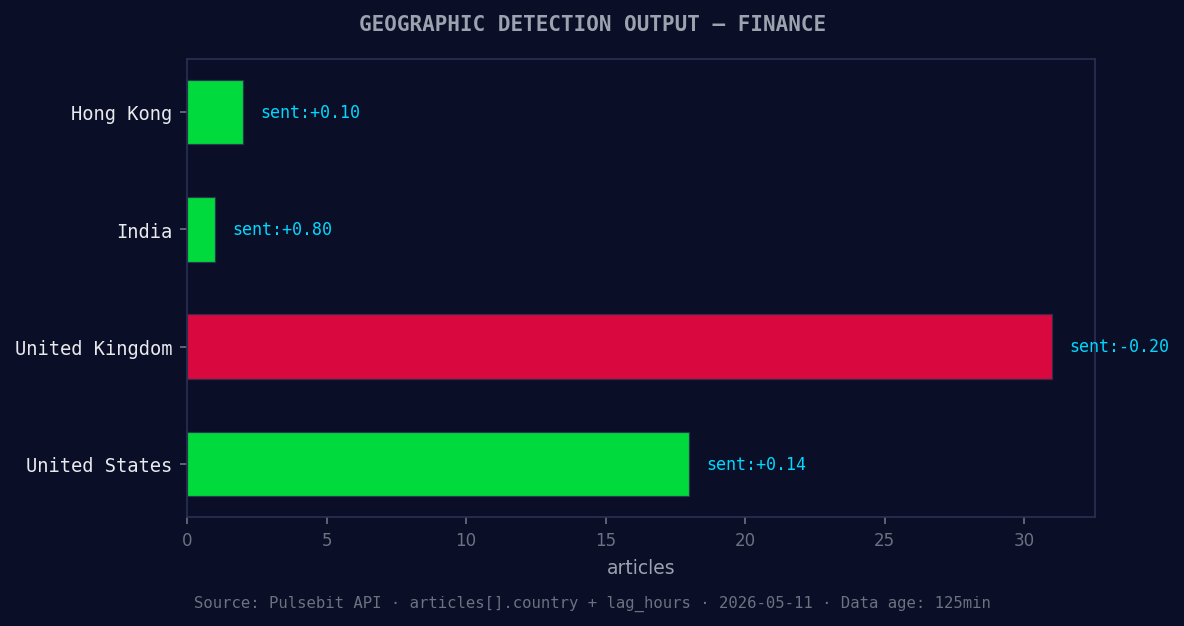
*Geographic detection output for finance. Hong Kong leads with 2 articles and sentiment +0.10. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
# Using the obtained data to score the narrative framing
cluster_reason_string = "Clustered by shared themes: strongest, corner, just, got, hit."
# Step 2: Meta-sentiment moment
sentiment_response = requests.post('https://api.pulsebit.com/sentiment', json={
'input': cluster_reason_string,
'score': -0.136,
'confidence': 0.95,
'momentum': -1.287
})
sentiment_data = sentiment_response.json()
print(sentiment_data)
This script first filters for Spanish-language articles on finance. It then retrieves sentiment data related to the clustered reasons, allowing us to evaluate the narrative framing effectively. This dual approach is essential; it ensures we’re not only catching the sentiment wave but also understanding the context behind it.
Now, let’s explore three specific builds you could implement with this newfound insight:
Geo-filtered Alert System: Create a system that triggers alerts when Spanish-language finance articles reflect a momentum score below a certain threshold, like -1.287. This ensures you’re notified instantly when sentiment starts to shift.
Meta-sentiment Analysis Dashboard: Build a dashboard that visualizes the sentiment scores of clustered narratives over time. You can use the meta-sentiment loop to analyze phrases like "forming: finance(+0.00), financial(+0.00), bill(+0.00)," contrasting them against mainstream themes to identify emerging stories before they hit larger audiences.
Adaptive Content Recommendations: Leverage the insights from the Spanish press to adapt your content strategy. If you notice a consistent sentiment drop around themes like "Johannesburg's financial crisis," consider producing content that addresses these issues directly, ensuring you engage your audience with relevant topics.
Ready to take the next step? You can find everything you need to get started at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can copy-paste and run this in under 10 minutes, and start catching those sentiment leads that could make a difference in your strategy.

Top comments (0)