Your pipeline just missed a significant anomaly: a 24h momentum spike of +0.373 in the sentiment around the topic of science. This is not just a minor uptick; it signals an important shift in sentiment that could have implications for your models and strategies. If your system isn’t accounting for multilingual origins or entity dominance effectively, you could be left in the dust. In this case, the leading language was English, lagging behind by 23.3 hours. That’s a critical window where valuable insights were overlooked.

English coverage led by 23.3 hours. Da at T+23.3h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
This gap highlights a common problem in many sentiment analysis pipelines: they often fail to account for the nuances of language and the dominance of certain entities in global discourse. Your model missed this spike by over 23 hours, which could mean the difference between leveraging a trending conversation and completely missing it. When English press is leading the conversation, it's evident that the language barrier and structural gaps in your processing may be costing you critical insights.
To catch this anomaly, we can leverage our API to filter and analyze the sentiment around science. Here’s how you can implement this in Python:
import requests
# Define parameters for the API call
topic = 'science'
score = +0.373
confidence = 0.75
momentum = +0.373
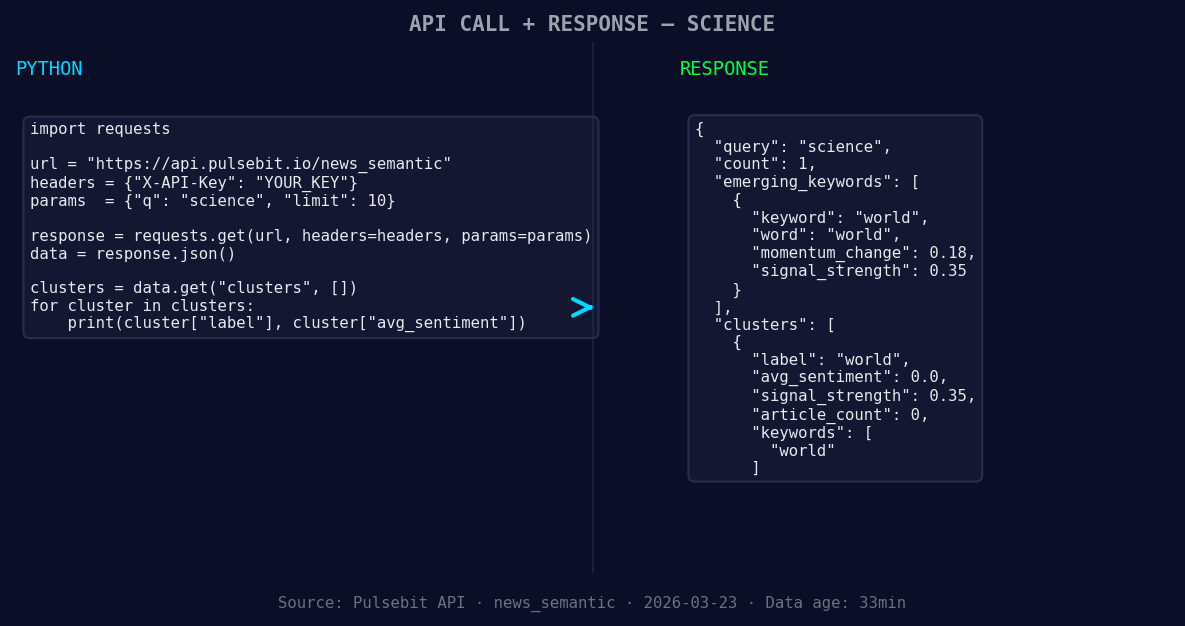
*Left: Python GET /news_semantic call for 'science'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
response = requests.get(
'https://api.pulsebit.io/sentiment',
params={
'topic': topic,
'momentum': momentum,
'lang': 'en' # Only English language
}
)
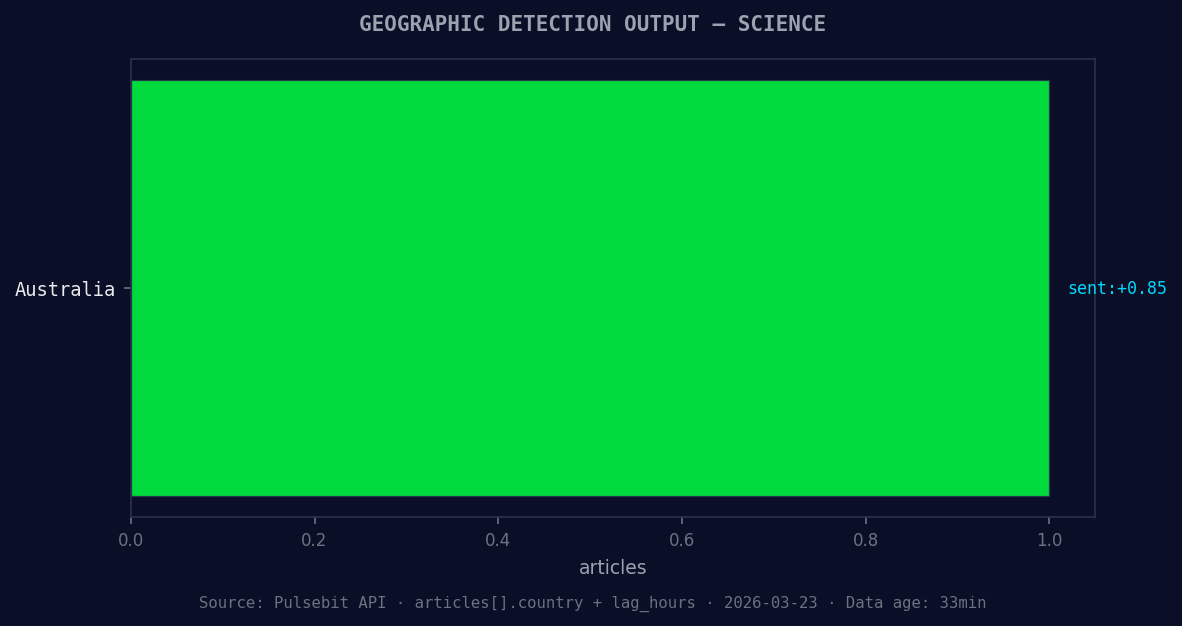
*Geographic detection output for science. Australia leads with 1 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
# Assuming the response contains 'data' in JSON format
data = response.json()
# Run the cluster reason string back through POST /sentiment
cluster_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_response = requests.post(
'https://api.pulsebit.io/sentiment',
json={'text': cluster_reason}
)
# Output the results
print(data)
print(meta_sentiment_response.json())
This code snippet does two critical things: it filters the sentiment data for the English language and queries the API for the sentiment around your cluster reason. This will help you gauge how the narrative is being framed, despite the limitations of the semantic structure.
Here are three specific builds you can create with this pattern:
Signal Analysis with Geo Filter: Use the endpoint to analyze sentiment spikes for specific topics across different languages. Set your threshold at a momentum of +0.373 and observe how sentiment varies in non-English articles. This can help identify emerging trends that English sources may miss.
Meta-Sentiment Loop for Narrative Framing: After you identify a spike, run the narrative framing through our sentiment endpoint. Use the cluster reason string to assess how incomplete semantic structures might be impacting the overall sentiment score. This can refine your understanding of why certain narratives are gaining traction.
Forming Themes Comparison: Utilize the forming sentiment around topics like "world" with a +0.18 score against mainstream sentiment. This could lead to the discovery of alternative narratives that are gaining momentum in different languages and communities, allowing you to pivot your strategy accordingly.
For more detailed examples and to get started, visit our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code and run this in under 10 minutes. Don't let your pipeline fall behind; leverage these insights to stay ahead of the curve.

Top comments (0)