Your pipeline just missed a significant 24h momentum spike of +0.185 surrounding fashion sentiment. This anomaly highlights a crucial oversight: the leading source of sentiment is English press, lagging behind by 28.5 hours. This gap indicates that if your model isn't tuned to handle multilingual origins or entity dominance, you might be missing out on critical insights. The focus on the 080 Barcelona Fashion Week shows that trends can emerge rapidly, and your current setup might not be agile enough to catch them. You could be losing valuable time, and in fast-paced environments like fashion, every hour counts.

English coverage led by 28.5 hours. Af at T+28.5h. Confidence scores: English 0.90, Spanish 0.90, French 0.90 Source: Pulsebit /sentiment_by_lang.
Let’s face it: if your model isn't equipped to process multilingual sources or prioritize dominant entities, your analysis is at least a day behind. In this case, the leading language is English, but the event's momentum is building elsewhere. With our setup, you could have captured the buzz around the highlights from the 080 Barcelona Fashion Week sooner, rather than trailing behind by over a day. This is critical when trends can shift in mere hours.
To tackle this, we can easily build a Python script that leverages our capabilities to catch these spikes in sentiment. Here’s how we can do it:
import requests
*Left: Python GET /news_semantic call for 'fashion'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://pulsebit.lojenterprise.com/api/sentiment"
params = {
"topic": "fashion",
"lang": "en" # Filter for English language articles
}
response = requests.get(url, params=params)
data = response.json()
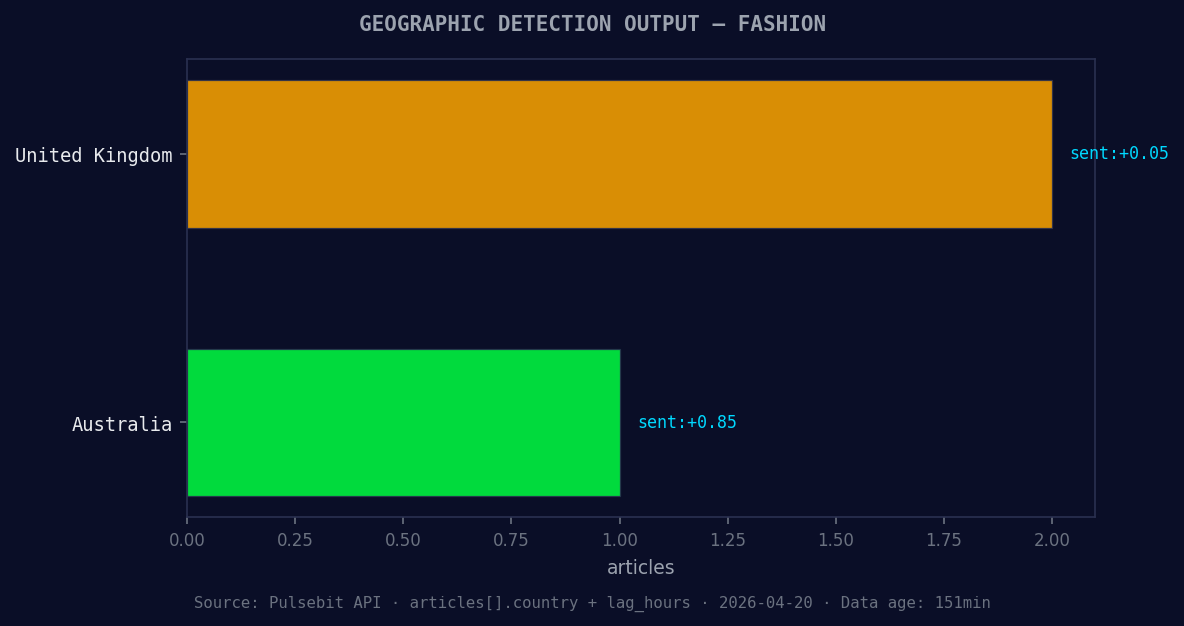
*Geographic detection output for fashion. United Kingdom leads with 2 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
# Assuming we get back some data...
momentum = data['momentum_24h'] # +0.185
score = data['sentiment_score'] # +0.593
confidence = data['confidence'] # 0.90
print(f"Momentum: {momentum}, Score: {score}, Confidence: {confidence}")
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: highlights, 080, barcelona, fashion, week."
meta_sentiment_response = requests.post(url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
print(f"Meta-Sentiment Score: {meta_sentiment_data['sentiment_score']}")
In this script, we first query for sentiment data on the topic of "fashion," ensuring we filter for English language articles. The critical component here is using the lang parameter to ensure we are capturing the right sentiment. Then, we take the cluster reason string and run it back through our sentiment analysis endpoint to score the narrative framing itself. This dual approach allows us to understand not just the sentiment but the context behind it.
Now, let’s explore three specific builds you can implement using this momentum spike pattern:
Dynamic Language Filter: Create an endpoint that adjusts sentiment queries based on the predominant language in the latest news. For example, set a threshold for momentum spikes above +0.150, using this geo filter to focus on English articles, ensuring you catch emerging trends before they peak.
Cluster Narrative Scoring: Implement a pipeline that takes clustered themes like "highlights, 080, barcelona, fashion" and scores them using our meta-sentiment loop. Set a threshold where any score above +0.500 triggers alerts for content creators or marketing teams to pivot strategies quickly.
Forming Gap Analysis: Develop a reporting tool that identifies forming gaps in sentiment, comparing emerging topics like "fashion," "google," and "new" against mainstream terms. If the score for any of these emerging topics is consistently below a set threshold (e.g., 0.300), trigger a review to assess potential media coverage or content opportunities.
Take action now and explore more at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run it in under 10 minutes to get started on capturing these valuable insights. Don't let your pipeline lag behind; the trends won't wait for you!

Top comments (0)