Your pipeline just missed a critical 24-hour momentum spike of -0.424 related to investing sentiment. This anomaly should raise eyebrows, especially considering the leading narrative around RIAs building and investing in data warehouses and in-house AI tools. With English press coverage leading the charge at 23.3 hours, it’s clear that there’s a significant lag in how sentiment is being captured and processed. If your model isn’t tuned to address multilingual origins or entity dominance, you’ve just been left behind by nearly a full day.

English coverage led by 23.3 hours. Et at T+23.3h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
When you consider that our primary sentiment is focused on “investing” while the leading language is English, it becomes apparent that your model could have missed this crucial insight by over 23 hours. This reflects a structural gap in any pipeline that doesn’t account for these nuances.
Let’s dive into the Python code that you can use to catch this critical sentiment shift before it’s too late. First, we need to filter for the geographic origin, specifically English-speaking content:
import requests
# Define parameters for the API call
params = {
"topic": "investing",
"lang": "en"
}
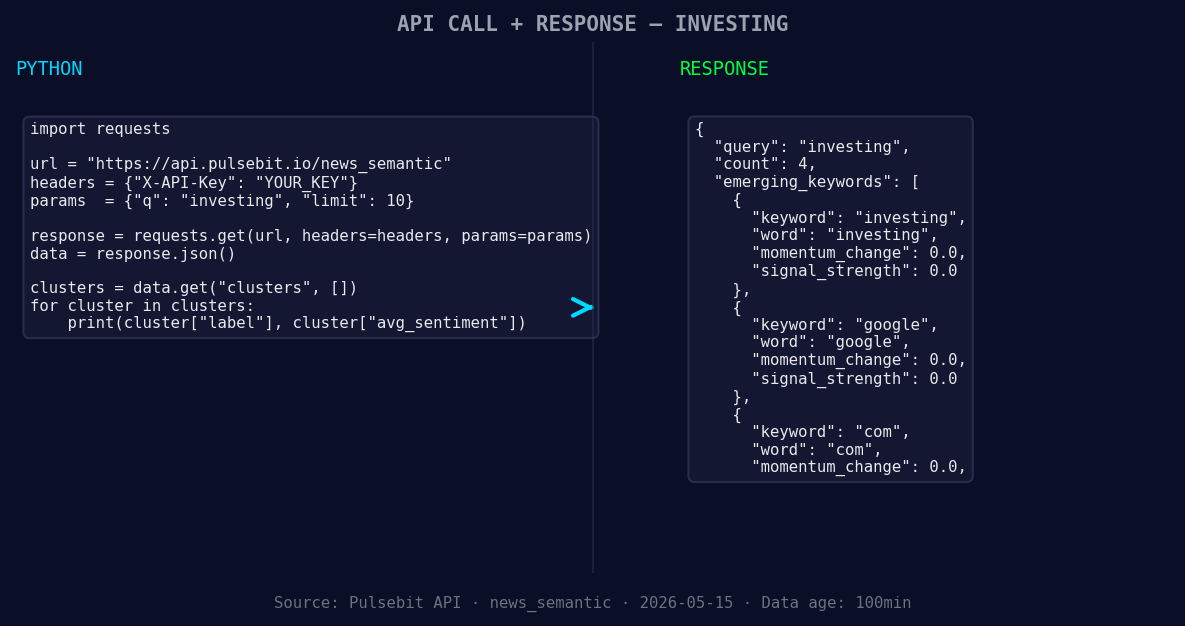
*Left: Python GET /news_semantic call for 'investing'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Make the API call
response = requests.get('https://api.pulsebit.com/sentiment', params=params)
data = response.json()
# Check the response
print(data)
Next, we’ll process the cluster reason string through our sentiment analysis endpoint. This allows us to score the narrative framing itself, which adds another layer to our understanding of the data.
# Define the narrative for meta-sentiment
meta_narrative = "Clustered by shared themes: building, investing, data, warehouses, in-house."
# POST request to get sentiment score for the narrative
meta_response = requests.post('https://api.pulsebit.com/sentiment', json={"text": meta_narrative})
meta_data = meta_response.json()
# Output the sentiment score for the narrative
print(meta_data)
With this foundation laid out, here are three specific builds you can implement tonight:
- Geo-Filtered Sentiment Analysis: Create a pipeline that continuously queries our API with the geographic filter set to "en" for the topic "investing." Set a threshold for momentum spikes above 0.5 to trigger alerts for potential investments.

Geographic detection output for investing. India leads with 2 articles and sentiment +0.78. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Scoring: Set up a routine that processes the cluster reasons back through the sentiment endpoint every hour. This allows you to capture shifts in narrative framing that could impact your decision-making.
Dynamic Threshold Alerts: Implement a system that notifies you when sentiment scores change drastically, particularly focusing on forming themes like “investing” and “google.” Utilize the 24-hour momentum metric to determine whether to pivot your strategy based on emerging trends.
These builds leverage the forming themes of investing, which are currently showing a score of +0.00 against mainstream topics. You can get started with this in just a few minutes. Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes to stay ahead of the curve.

Top comments (0)