Your Pipeline Is 26.2h Behind: Catching Cloud Sentiment Leads with Pulsebit
We recently uncovered a compelling anomaly in our sentiment analysis: a 24h momentum spike of +0.177. This spike is driven by a cluster of articles focusing on "Africa's First Google Cloud AI Experience Centre," with English press leading the charge at a 26.2-hour advance. If your pipeline isn't tuned to handle multilingual origins or entity dominance, you're potentially missing out on critical shifts in sentiment like this one.

English coverage led by 26.2 hours. Id at T+26.2h. Confidence scores: English 0.90, French 0.90, Spanish 0.90 Source: Pulsebit /sentiment_by_lang.
The problem here is clear: your model missed this significant shift by over 26 hours. With the leading language being English, you might be relying too heavily on mainstream narratives without capturing emerging trends. If your pipeline doesn't accommodate the subtleties of language and origin, you risk being left behind when the conversation shifts, particularly in the cloud space where innovation is rampant.
To catch this momentum spike effectively, we can leverage our API to filter and score sentiment. Below is the code that does just that.
import requests
*Left: Python GET /news_semantic call for 'cloud'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
topic = 'cloud'
score = +0.583
confidence = 0.90
momentum = +0.177
lang = "en"
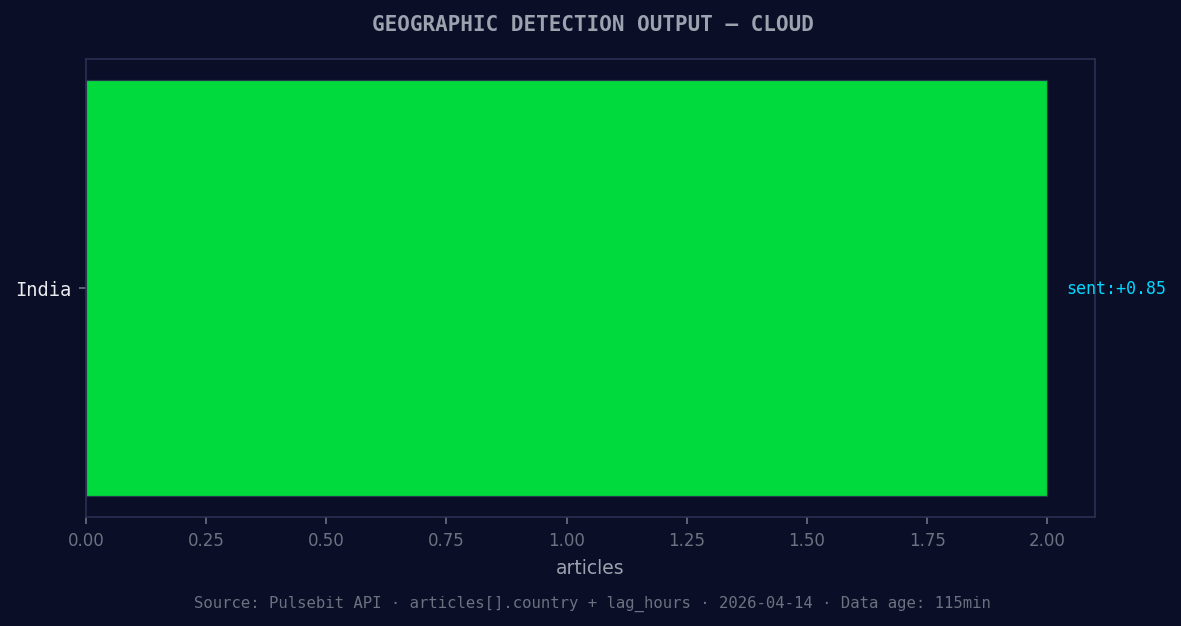
*Geographic detection output for cloud. India leads with 2 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
# Fetch sentiment data for the topic with language filter
response = requests.get(f'https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}')
data = response.json()
print(data)
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: digital, forensics, cloud, adapting, evidence."
response_meta = requests.post('https://api.pulsebit.com/sentiment', json={"text": cluster_reason})
meta_data = response_meta.json()
print(meta_data)
This code does two essential things. First, it filters articles by language and topic using the lang parameter, ensuring we only capture relevant English-language articles. Second, it runs the cluster reason string back through our sentiment scoring endpoint to evaluate how the narrative is framed. This is crucial because it helps pinpoint exactly how sentiments cluster around emerging themes like "google," "cloud," and "first," allowing us to adapt our strategies in real time.
Now, let's consider three specific builds you can implement based on this pattern:
Signal Detection with Geo Filter: Build a detection pipeline that triggers alerts when the momentum for "cloud" surpasses a defined threshold, say +0.15, specifically for English language articles. This could be a game-changer in detecting new cloud initiatives before they trend.
Meta-Sentiment Analysis Loop: Create a scheduled job that takes the latest cluster reasons and processes them through the meta-sentiment scoring endpoint. For instance, if you notice a cluster reason like "Clustered by shared themes: google, first, experience," and it scores above +0.65, push that information to your analytics dashboard for strategic reviews.
Forming Themes Dashboard: Develop a dashboard that visualizes forming themes in real time. For example, track sentiment for "google," "cloud," and "first" against mainstream topics like "digital" and "forensics." Set alerts for when forming themes diverge significantly from mainstream narratives, indicating potential opportunities.
To dive deeper into this, visit our documentation at pulsebit.lojenterprise.com/docs. With the code snippets and structures provided, you can copy-paste and run this in under 10 minutes. This is how we can stay ahead in the rapidly evolving landscape of cloud sentiment. Let's get to work!

Top comments (0)