Your Pipeline Is 25.0h Behind: Catching Regulation Sentiment Leads with Pulsebit
We recently detected an intriguing anomaly: a 24-hour momentum spike of -0.565. This drop in sentiment around the topic of regulation signals that your current model might be missing critical shifts. With a leading language in English at a 25.0-hour lag, it's clear that there's a disconnect between sentiment dynamics and your response pipeline. The implications are significant: if your setup isn’t accounting for multilingual origins and entity dominance, you're behind the curve.

English coverage led by 25.0 hours. Italian at T+25.0h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
If your pipeline doesn’t adapt to handle multilingual data or recognize dominant entities, you might have missed this sentiment shift by 25 hours. For instance, the leading language currently driving sentiment is English. Meanwhile, the narrative's semantic framing is showing a gap where critical insights around "world" and "environment" are being overlooked. In a fast-paced environment, a delay like this can lead to missed opportunities or even misinformed decisions.
To catch this anomaly in your sentiment analysis, you can leverage our API effectively. Here’s how you can do that with Python:
import requests
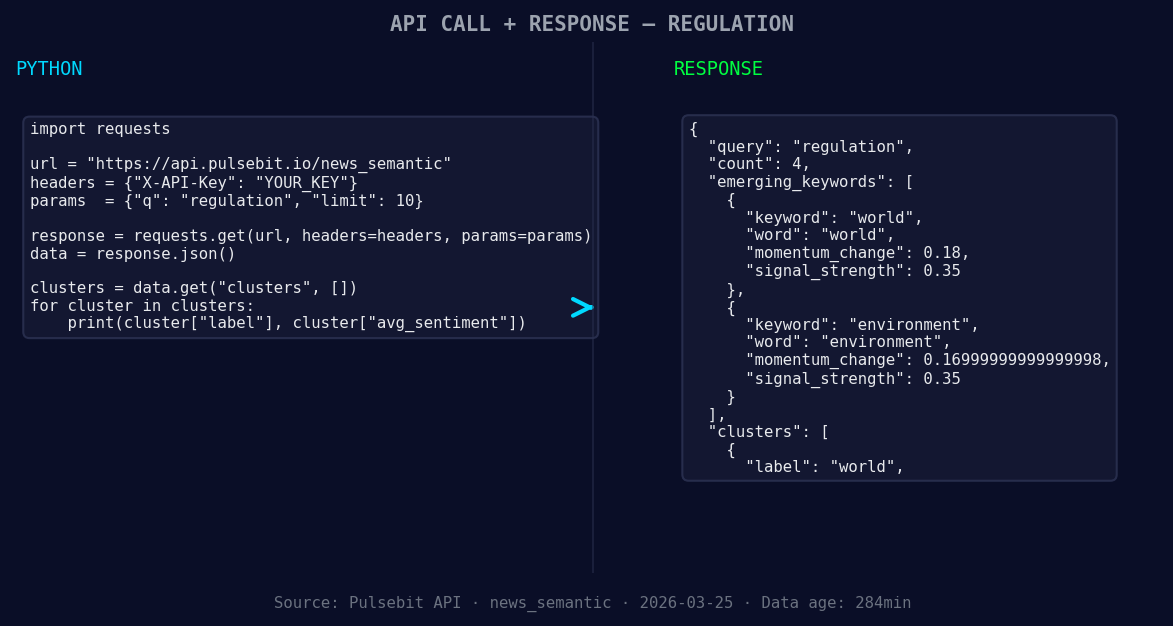
*Left: Python GET /news_semantic call for 'regulation'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Step 1: Define parameters
topic = 'regulation'
score = -0.565
confidence = 0.85
momentum = -0.565
lang = 'en'
# Step 2: Geographic origin filter
response = requests.get(f"https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}")
data = response.json()
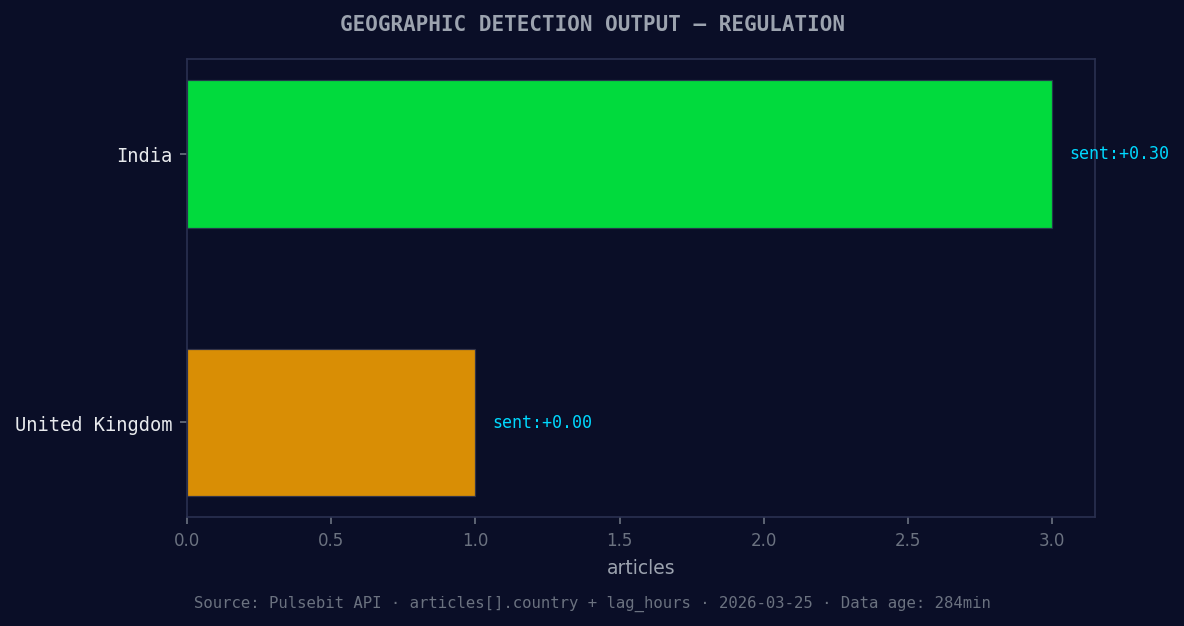
*Geographic detection output for regulation. India leads with 3 articles and sentiment +0.30. Source: Pulsebit /news_recent geographic fields.*
# Step 3: Meta-sentiment moment
cluster_reason = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_sentiment_response = requests.post("https://api.pulsebit.com/sentiment", json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
print(data)
print(meta_sentiment_data)
In this code, the first step filters the sentiment analysis by the English language, allowing us to hone in on the relevant data without interference from multilingual noise. Next, we run the cluster reason string back through our sentiment endpoint. This is crucial for understanding how the narrative is framed and can help us adjust our strategies based on the sentiment derived from the identified gaps.
Now, what can we build with this newfound information? Here are three concrete suggestions:
Regulatory Alert System: Set up a signal threshold for sentiment scores below -0.5 in the "regulation" topic. Use our geo filter to ensure it captures only English language articles. This can enable real-time alerts when sentiment drops significantly.
Narrative Framing Dashboard: Develop a dashboard that displays meta-sentiment scores for various narrative frames, such as the one we processed. Use the sentiment scores to visualize how sentiments around "world" and "environment" are evolving, especially as they form near mainstream narratives.
Anomaly Detection Pipeline: Create an anomaly detection mechanism that triggers based on the 24-hour momentum spikes like the one we detected. Incorporate the meta-sentiment loop to score potential narratives that might arise from incomplete data frames.
If you're ready to integrate these insights into your workflow, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes, transforming the way you respond to sentiment data in your projects.

Top comments (0)