Your Pipeline Is 26.6h Behind: Catching World Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly where the 24h momentum spike hit +0.684. This isn't just a number; it’s a clear indication that we have a significant shift in sentiment around a topic that most pipelines are missing. The leading language for this spike is English, which is lagging behind German press coverage by 26.6 hours.
This reveals a critical structural gap in your sentiment analysis pipeline if it doesn't accommodate multilingual origins or entity dominance. Imagine this: your model missed the opportunity to catch a world record-breaking story about a humanoid robot in Beijing because it wasn't set up to recognize the urgency in English sentiment. By the time your analysis catches up, you're already 26.6 hours behind the curve.

English coverage led by 26.6 hours. German at T+26.6h. Confidence scores: English 0.85, Italian 0.85, Sv 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike, you need to leverage our API effectively. Here’s how you can do it in Python:
import requests
# Step 1: Geographic origin filter
url = 'https://api.pulsebit/endpoint'
params = {
"topic": "world",
"lang": "en",
"score": -0.053,
"confidence": 0.85,
"momentum": +0.684
}
response = requests.get(url, params=params)
data = response.json()
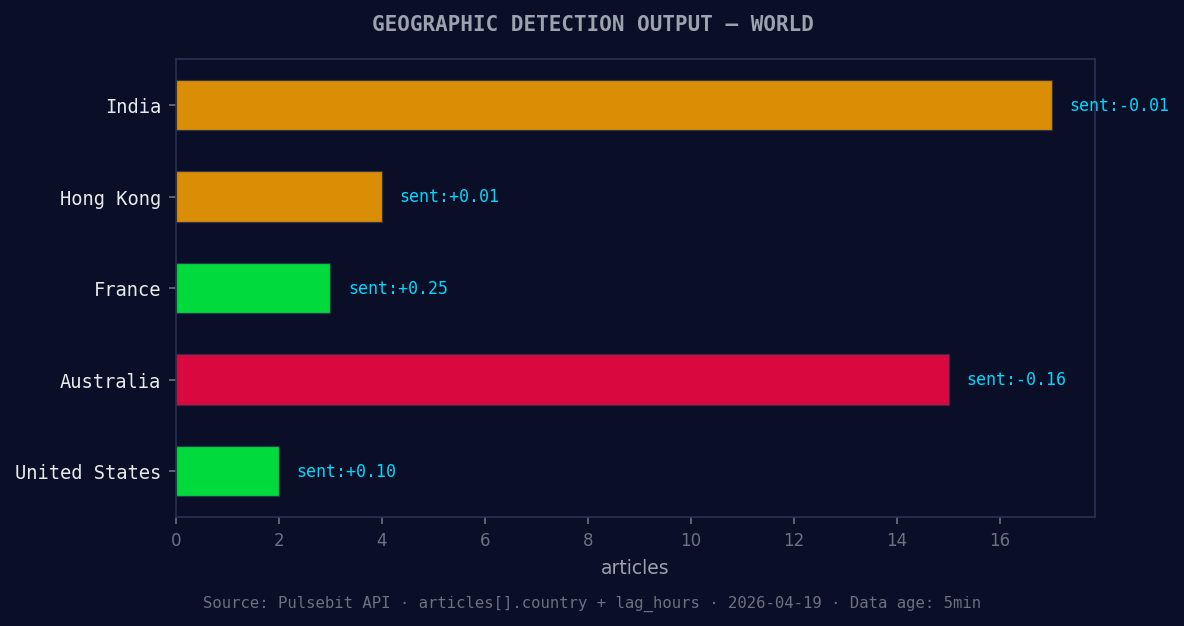
*Geographic detection output for world. India leads with 17 articles and sentiment -0.01. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: administration, warms, imf, world, bank."
sentiment_response = requests.post('https://api.pulsebit/sentiment', json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print(data)
print(sentiment_data)
In the first step, we filter by the English language to ensure that we capture the relevant articles discussing the world record. The API call fetches sentiment data that will help us analyze this specific momentum. Next, we run the grouped narrative through our sentiment endpoint to score the framing of the cluster reason itself. This is crucial because it gives you insight into how the narrative is developing based on the themes being discussed.

Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Now let’s jump into a few specific builds you can implement right away to take advantage of this insight:
Geo-filtered Sentiment Analysis: Use the geographic origin filter with the topic 'world' and set the momentum threshold to +0.684. This will allow you to monitor similar spikes in sentiment around international events.
Meta-Sentiment Loop: Initiate a meta-sentiment loop on the cluster reason. Input: "Clustered by shared themes: robot, world, record, beijing, breaks." This will give you a granular understanding of how various narratives are emerging within the same thematic space.
Theme Comparison: Set up a comparison between forming themes like 'world(+0.00)', 'google(+0.00)', 'robot(+0.00)' against mainstream topics such as 'administration', 'warms', 'imf'. This will help you identify any potential sentiment shifts and prompt you to react faster.
You can get started immediately by diving into our documentation at pulsebit.lojenterprise.com/docs. The exit test is straightforward: you should be able to copy, paste, and run this in under 10 minutes. Don’t let your pipeline fall behind; keep it agile and responsive to these emerging trends!

Top comments (0)