Your pipeline just missed a critical anomaly: a 24h momentum spike of -0.701 for the topic of defence. This decline suggests a significant shift in sentiment that could inform your decision-making process. With the leading language being English and the data lagging behind by 15.1 hours, it's clear that something important is happening that your current model isn't capturing in real-time. This discrepancy highlights an underlying issue in how sentiment data is processed, especially when accounting for multilingual origins and the dominance of specific entities.

English coverage led by 15.1 hours. Id at T+15.1h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
If your model doesn't handle these nuances, you may find that you're consistently late to actionable insights. In this case, you missed a spike 15.1 hours ago, which is a significant window in the fast-paced world of sentiment analysis. With English press leading the discussion but providing zero articles on the topic of "world," we see the potential for missed opportunities in understanding how defence sentiment is shaping up globally. The gap in your pipeline is not just a delay; it's a structural flaw that could lead to missed strategic insights.
Here's a Python snippet that can help you catch these sentiments before they become stale. We’ll start by querying our data for the topic of defence, using the momentum and confidence levels we’ve identified:
import requests
# Define parameters for the API call
topic = 'defence'
score = -0.701
confidence = 0.75
momentum = -0.701
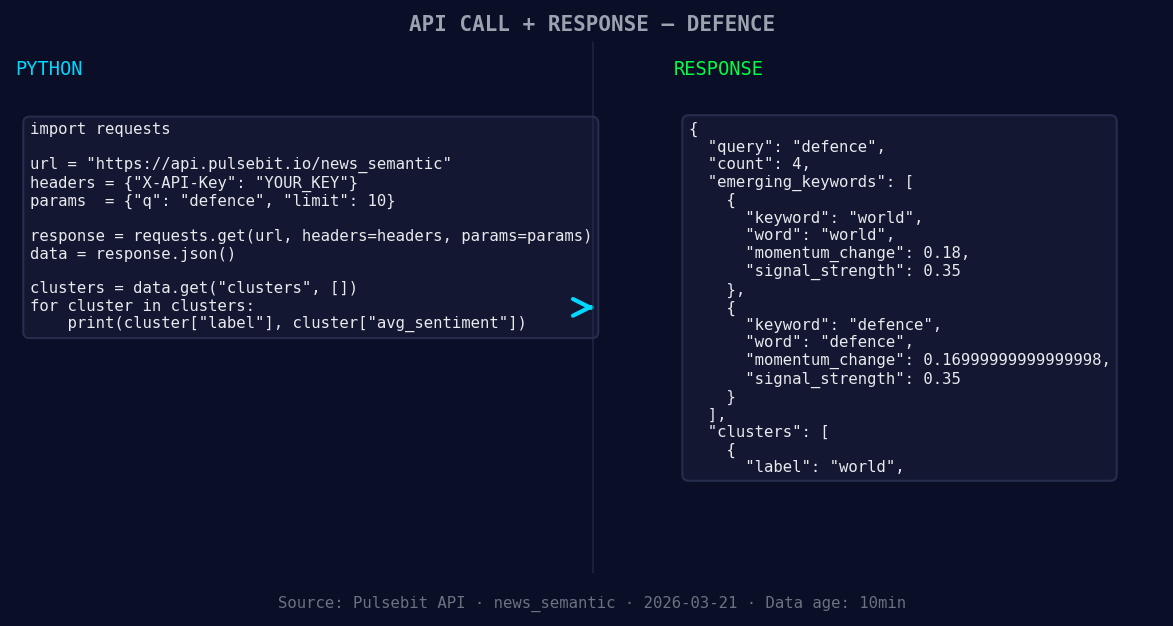
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 1). Source: Pulsebit /news_semantic.*
# Geographic origin filter - only English language articles
url = 'https://api.pulsebit.com/sentiment'
params = {
'topic': topic,
'momentum': momentum,
'confidence': confidence,
'lang': 'en'
}
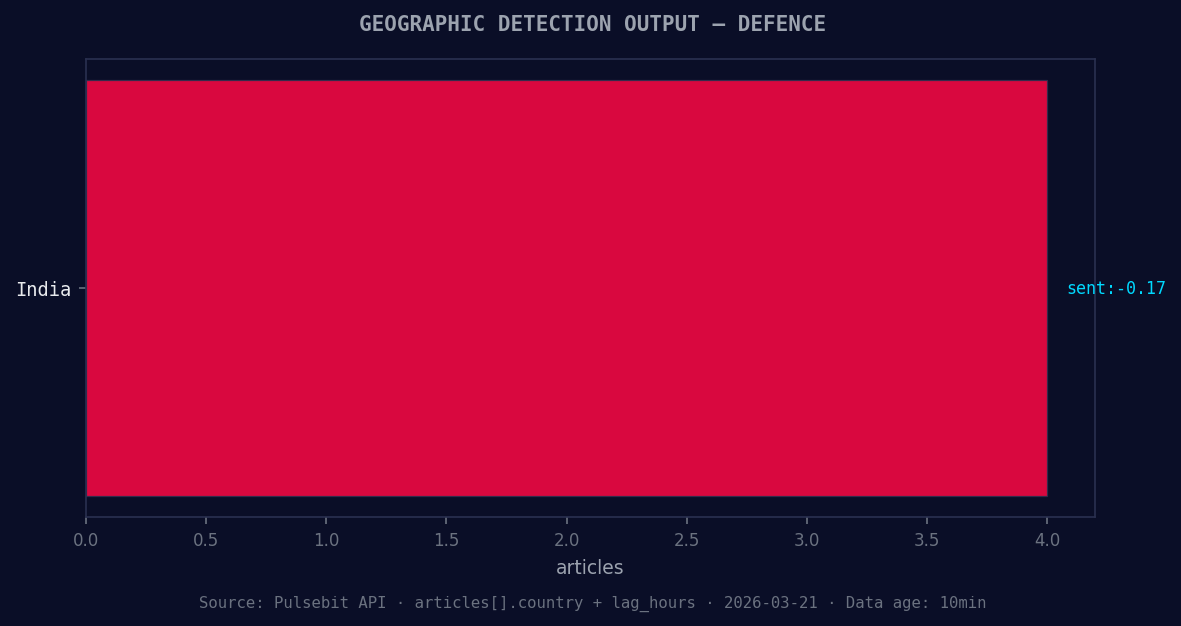
*Geographic detection output for defence. India leads with 4 articles and sentiment -0.17. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get(url, params=params)
data = response.json()
print(data)
Next, we want to evaluate the meta-sentiment around our cluster reason: "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence." This will allow us to score the narrative framing itself, which can be critical in understanding the underlying sentiment.
# Meta-sentiment moment
meta_sentiment_url = 'https://api.pulsebit.com/sentiment'
meta_input = "Semantic API incomplete — fallback semantic structure built from available keywords and article/search evidence."
meta_response = requests.post(meta_sentiment_url, json={'text': meta_input})
meta_data = meta_response.json()
print(meta_data)
With this code, we can quickly gain insights into the current sentiment landscape. Now let's think about three specific builds we can create based on this anomaly.
Forming Signals: Set a threshold for negative sentiment spikes like -0.701 on the defence topic. Use this as a signal to trigger alerts when similar sentiment falls below this threshold, allowing you to react faster.
Geo Filter Implementation: Create a custom dashboard that visualizes sentiment trends using the geographic origin filter. This will help you identify regions where defence sentiment is shifting, giving you a tactical advantage over competitors who may overlook regional variations.
Meta-Sentiment Analysis: Build an endpoint that continuously runs the meta-sentiment loop for any incomplete semantic structures detected in your articles. This will help you refine your understanding of narratives around key topics, like "world" and "defence," which are currently forming at +0.18 and +0.17, respectively.
To get started, check out our documentation at pulsebit.lojenterprise.com/docs. With the provided code, you can copy, paste, and run this in under 10 minutes. Don't let another critical sentiment shift slip through the cracks.

Top comments (0)